This is the first of what may become an occasional series of interviews with people in the data mining field. Eric Siegel is the organizer of the popular Predictive Analytics World conference series. I asked him a little bit about himself and gave him a chance to plug his conference. A propos, readers of this blog can get a 15% discount on a two-day conference pass by pasting the code DATAMINER010 into the Promotional Code box on the conference
registration page.
Q: Not many kids (one of mine is perhaps the exception that proves the rule) have the thought "when I grow up, I want to be a data miner!" How did you fall into this line of work?
To many laypeople, the word "data" sounds dry, arcane, meaningless - boring! And number-crunching on it doubly so. But this is actually the whole point. Data is the uninterpreted mass of things that've happened. Extracting what's up, the means behind the madness, and in so doing modeling and learning about human behavior... well, I feel nothing in science or engineering is more interesting.
In my "previous life" as an academic researcher, I focused on core predictive modeling methods. The ability for a computer to automatically learn from experience (data really is recorded experience, after all), is the best thing since sliced bread. Ever since I realized, as I grew up from childhood, that space travel would in fact be a tremendous, grueling pain in the neck (not fun like "Star Wars"), nothing in science has ever seemed nearly as exciting.
In my current 9-year career as a commercial practitioner, I've found that indeed the ability to analytically "learn" and apply what's been learned turns out to provide plenty of business value, as I imagined back in the lab. Research science is fun in that you have the luxury of abstraction and are often fairly removed from the need to prove near-term industrial applicability. Applied science is fun for the opposite reason: The tangle of challenges, although some less abstract and in that sense more mundane, are the only thing between you and getting the great ideas of the world to actually work, come to fruition, and deliver an irrefutable impact.
Q: Most conferences happen once a year. Why does PAW come around so much more frequently?
In fact, many commercial conferences focused the industrial deployment of technology occur multiple times per year, in contrast to research conferences, which usually take place annually. There's an increasing demand for a more frequent commercial event as predictive analytics continues to "cross chasms" towards more widescale penetration. There's just too much to cover - too many brand-name case studies and too many hot topics - to wait a year before each event.
Q: You use the phrase "predictive analytics" for what I've always called "data mining." Do the terms mean something different, or is it just that fashions change with the times?
"Data mining" is indeed often used synonymously with "predictive analytics", but not always. Data mining's definitions usually entail the discovery of non-trivial, useful patterns/knowledge/insights from data -- if you "dig" enough, you get a "nugget." This is a fairly abstract definition and therefore envelops a wide range of analytical techniques. On the other hand, predictive analytics is basically the commerical deployment of predictive modeling specifically (that is, in academic jargon, supervised learning, i.e., optimizing a statitistical model over labeled/historical cases). In business applications, this basically translates to a model that produces a score for each customer, prospect, or other unit of interest (business/outlet location, SKU, etc), which is roughly the working definition we posted on the Predictive Analytics World website. This would seem to potentially exclude related data mining methods such as forecasting, association mining and clustering (unsupervised learning), but, naturally, we include some sessions at the conference on these topics as well, such as your extremely-well-received session on forecasting October 2009 in DC.
Q: How do you split your time between conference organizing and analytical consulting work? (That's my polite way of trying to rephrase a question I was once asked: "What's the split between spewing and doing?")
When one starts spewing a lot, there becomes much less time for doing. In the last 2 years, as my 2-day seminar on predictive analytics has become more frequent (both as public and customized on-site training sessions - see
http://www.businessprediction.com), and I helped launch Predictive Analytics World, my work in services has become less than half my time, and I now spend very little time doing hands-on, playing a more advisory and supervisory role for clients, alongside other senior consultants who do more hands-on for Prediction Impact services engagements.
Q: I can't help noticing that you have a Ph.D. As someone without any advanced degrees, I'm pretty good at rationalizing away their importance, but I want to give you a chance to explain what competitive advantage it gives you.
The doctorate is a research-oriented degree, and the Ph.D. dissertation is in a sense a "hazing" process. However, it's become clear to me that the degree is very much net positive for my commercial career. People know it entails a certain degree of discipline and aptitude. And, even if I'm not conducting academic research most of the time, every time one applies analytics there there is an experimental component to the task. On the other hand, many of the best data miners - the "rock star" consultants such as yourself - did not need a doctorate program in order to become great at data mining.
Q: Moving away from the personal, how do you think the move of data and computing power into the cloud is going to change data mining?
I'd say there's a lot of potential in making parallelized deployment more readily available to any and all data miners. But, of all the hot topics in analytics, I feel this is the one into which I have the least visibility. It does, after all, pertain more to infrastucture and support than to the content, meaning and insights gained from analysis.
Q: Can you give examples of problems that once seemed like hot analytical challenges that have now become commoditized?
Great question. Hmm... common core analyical methods such as decision trees and logistic regression may be the only true commodities to date in our field. What do you think?
Q: There are some tasks that we used to get hired for 10 or 15 years ago that no one comes to us for these days. Direct mail response models is an example. I think people feel like they know how to do those themselves. Or maybe that is something the data vendors pretty much give away with the data.
Which of today's hot topics in data mining do you see as ripe for commiditization?
Expanding traditional data sets with SOCIAL DATA is continuing to gain traction across a growing range of verticals as analytics pracitioners find great value (read: tremendous increases in model lift) leveraging the simple fact that people behave similarly to those to whom they're socially connected. Just as the healthcare industry has discovered that quitting smoking is "contagious" and that the risk of obesity dramatically increases if you have an obese friend, telecommunications, online social networks and other industries find that "birds of a feather" churn and even commit fraud "together". Is this more because people influence one-another, or because they befriend others more like themselves? Either way, social connections are hugely predictive of the customer behaviors that matter to business.
Q: There have been several articles in the popular press recently, like this one in the NY Times, saying that statistics and data mining are the hottest fields a young person could enter right now. Do you agree?
Well, for the subjective reasons in my answer to your first question above, I would heartily agree. If I recall, that NY Times article focused on the demand for data miners as the career's central appeal. Indeed, it is a very marketable skill these days, which certainly doesn't hurt.
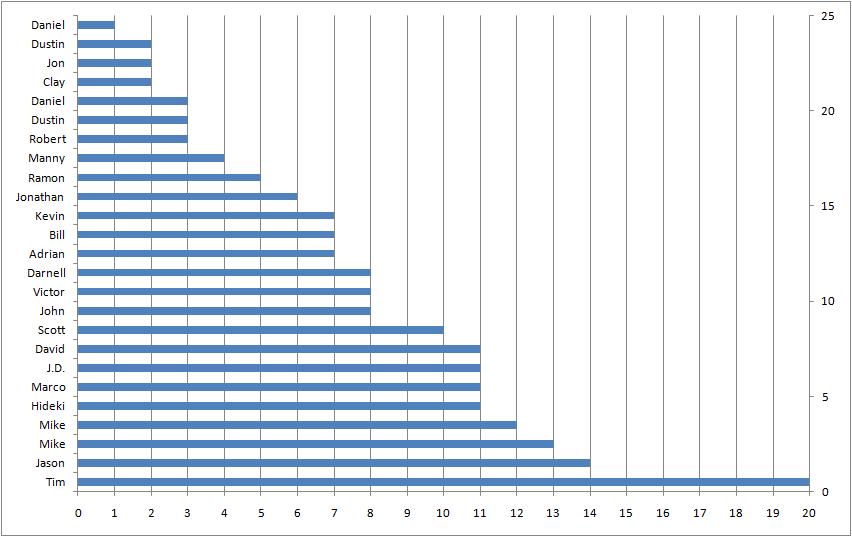
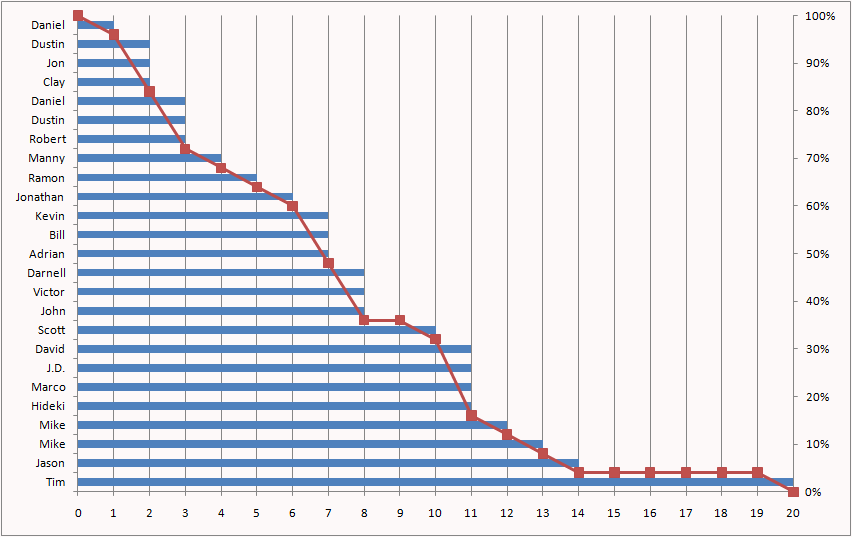
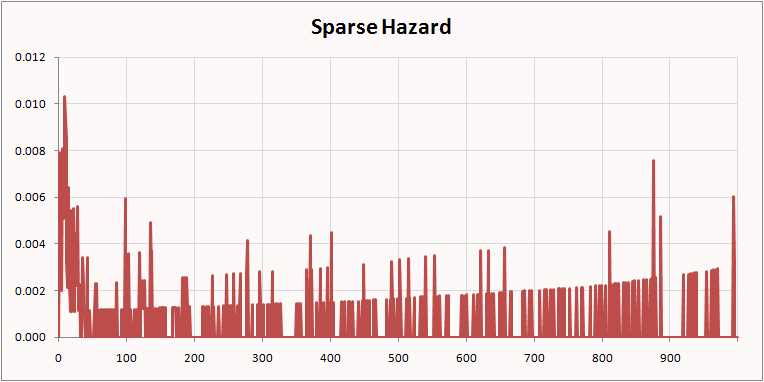
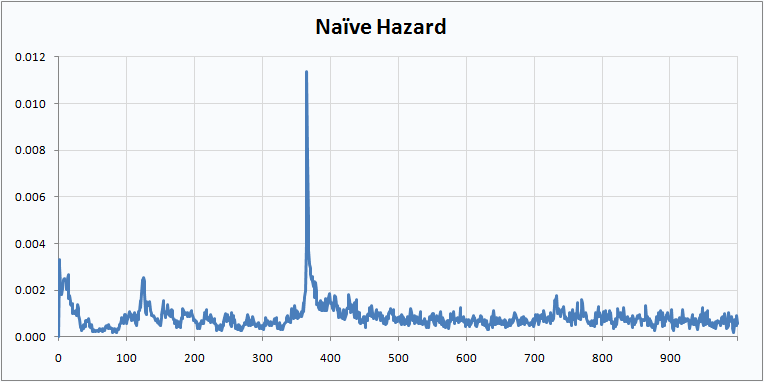




{kind=link}
{kind=link}
{kind=link}