The chi-square test can be applied to more than two dimensions. However, the multi-dimensional chi-square behaves a bit differently from the two-dimensional case. This posting describes why. The next posting describes the calculation for the multi-dimensional chi-square. And the third posting in this series will describe how to do the calculations using SQL.
Fast Overview of Chi-Square
The Chi-Square test is used when we have two or more categorical variables and counts of how often each combination appears. For instance, the following is a simple set of data in two dimensions:
| A=0 | B=0 | 1 | |
| A=0 | B=1 | 2 | |
| A=1 | B=0 | 3 | |
| A=1 | B=1 | 4 |
This data is summarized from ten observations. The first row says that in one data record, both A and B are zero. The last row says that in four of them, both A and B are 1. In practice, when using the chi-square test, we would want higher counts -- and we would get them, because these are counts of customers (say, responders and non-responders by gender).
In two dimensions, a contingency table is perhaps a better way of looking at the counts:
| B=0 | B=1 | ||
| A=0 | 1 | 2 | |
| A=1 | 3 | 4 |
The chi-square test then asks the question . . . What is the probability that the counts are produced randomly, assuming that both the A and B are independent? To answer this question, we need the expected values assuming independence between A and B. The following table shows the expected values:
| B=0 | B=1 | ||
| A=0 | 1.2 | 1.8 | |
| A=1 | 2.8 | 4.2 |
The expected values have two important properties. First, the row sums and column sums are the same as the original data. So, 1+2 = 1.2+1.8 = 3, and so on for both rows and both columns.
The second property is a little more subtle, but it says that the ratios of values in any column or any row are the same. So, 1.2/1.8 = 2.8/4.2 = 2/3, and so on. Of all possible 2X2 matrices, there is only one that has both these properties.
Now, the chi-square value for any cell is the square of the difference between the actual value and the expected value divided by the expected value. The chi-square for the matrix is the sum of the chi-square values for all the cells. These follow a chi-square distribution with one degree of freedom, and this gives us a enough information to determine whether the original counts are likely due to chance.
Calculating expected values is easy. The expected value for any cell is the product of the row sum times the column sum divided by the total in the table. For example, for A=0, B=0, the row sum is 3 and the column sum is 4. The product is 12, so the expected value is 1.2 = 12/10.
Treating Three Dimensions As Two Dimensions
Now, let's assume that the data has three dimensions rather than two. For example:
| A=0 | B=0 | C=0 | 1 | |
| A=0 | B=0 | C=1 | 2 | |
| A=0 | B=1 | C=0 | 3 | |
| A=0 | B=1 | C=1 | 4 | |
| A=1 | B=0 | C=0 | 5 | |
| A=1 | B=0 | C=1 | 6 | |
| A=1 | B=1 | C=0 | 7 | |
| A=1 | B=1 | C=1 | 8 |
We can treat this as a contingency table in two dimensions:
| C=0 | C=1 | ||
| A=0,B=0 | 1 | 5 | |
| A=0,B=1 | 2 | 6 | |
| A=1,B=0 | 3 | 7 | |
| A=1,B=1 | 4 | 8 |
And from this we can readily calculate the expected values:
| C=0 | C=1 | ||
| A=0,B=0 | 1.67 | 4.33 | |
| A=0,B=1 | 2.22 | 5.78 | |
| A=1,B=0 | 2.78 | 7.22 | |
| A=1,B=1 | 3.33 | 8.67 |
The chi-square calculation follows as in the earlier case. The chi-square value for each cell is the actual count minus the expected value squared divided by the expected value. The chi-square value for the entire table is the sum of all the chi-square values for each cell.
The only difference here is that there are three degrees of freedom. This affects how to transform the chi-square value into a probability, but it does not affect the computation.
Which Are the Right Expected Values?
There are actually two other continency tables that we might produce from the original 2X2X2 data, depending on which dimension we use for the columns:
| B=0 | B=1 | ||
| A=0,C=0 | 1 | 2 | |
| A=0,C=1 | 5 | 6 | |
| A=1,C=0 | 3 | 4 | |
| A=1,C=1 | 7 | 8 |
and
| A=0 | A=1 | ||
| B=0,C=0 | 1 | 3 | |
| B=0,C=1 | 5 | 7 | |
| B=1,C=0 | 2 | 4 | |
| B=1,C=1 | 6 | 8 |
Following the same procedure, we can calcualte the expected values for each of these.
| B=0 | B=1 | ||
| A=0,C=0 | 1.33 | 1.67 | |
| A=0,C=1 | 4.89 | 6.11 | |
| A=1,C=0 | 3.11 | 3.89 | |
| A=1,C=1 | 6.67 | 8.33 |
and
| B=0 | B=1 | ||
| A=0,C=0 | 1.78 | 2.22 | |
| A=0,C=1 | 5.33 | 6.67 | |
| A=1,C=0 | 2.67 | 3.33 | |
| A=1,C=1 | 6.22 | 7.78 |
Oops!. The three sets of expected values are different from each other. Which do we use for the 2X2X2 chi-square calculation?
Why Independence is a Strong Condition
The answer is none of these. For the three dimensional data (and higher dimensional as well), the three contingency tables are almost always going to be different, because they mean different things. This is perhaps best viewed geometrically:
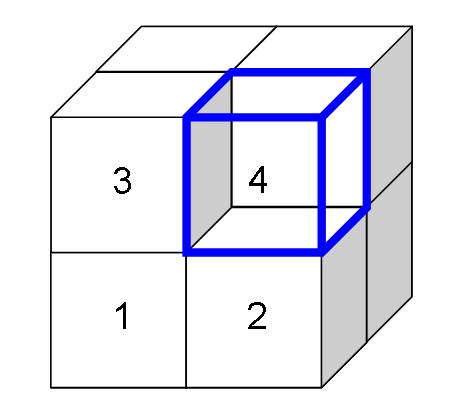
In this cube, the front face corresponds to C=0 and the hidden face to C=1. The A values go horizontally and the B's vertically. The three different contingency tables are formed by cutting the cube in half and then pasting the halves together. These tables are different.
For instance, the front face and the back facee are each 2X2 contingency tables. The expected values for these can be determined just from the information on each face. We do not need the information along the C dimension for this calculation. Worse, we cannot even use this information -- so there is no way to ensure that the sums along the "C" dimension add up to the same values in the original data and for the expected values.
The problem is that the sums along each dimension overspecify the problem. A given value has three adjacent values along three dimensions. However, only two of the dimensions are needed to calcualte an expected value, assuming independence along those two dimensions. The information along the third dimension cannot be incorporated into the calculation.
The reason? Independence is a very strong condition. Remember, it says not only that the sums are the same but also that the ratios within each row (or column or layer) are the same. Normally, we might think "independent" variables are providing as much flexibility as possible. However, that is not the case. In fact, the original counts are the only ones that meet the all the conditions of independence at the level of every row, colum, and level.
When I think of this situation, I think of a paradox related to the random distribution of stars. We actually perceive a random distribution as more ordered. Check out this site for an example. Similarly, our intuition is that independence among variables is a weak condition. In fact, it can be quite a strong condition.
The next posting will explain how expected values work in three and more dimensions. For now, it is worth explaining that converting a three-dimensional problem into two dimensions is often feasible and reasonable. This is particularly true when one of the dimensions is a "response" characteristic and the rest are input dimensions. However, such a 2X2 table is really an approximation.