For most data mining algorithms, the best representation of data is a single, flat table with one row for each object of study (a customer or a movie, for example), and columns for every attribute that might prove informative or predictive. We refer to these tables as signatures. Part of the data miner’s art is to create rich signatures from data that, at first sight, appears to have few features.
In our commercial data mining projects, we often deal with tables of transactions. Typically, there is very little data recorded for any one transaction. Fortunately, there are many transactions which, taken together, can be made to reveal much information. As an example, a supermarket loyalty card program generates identified transactions. For every item that passes over the scanner, a record is created with the customer number, store number, the lane number, the cash register open time, and the item code. Any one of these records does not provide much information. On a particular day, a particular customer’s shopping included a particular item. It is only when many such records are combined that they begin to provide a useful view of customer behavior. What is the distribution of shopping trips by time of day? A person who shops mainly in the afternoons has a different lifestyle than one who only shops nights and weekends. How adventurous is the customer? How many distinct SKU’s do they purchase? How responsive is the customer to promotions? How much brand loyalty do they display? What is the customer’s distribution of spending across departments? How frequently does the customer shop? Does the customer visit more than one store in the chain? Is the customer a “from scratch” baker? Does this store seem to be the primary grocery shopping destination for the customer? The answers to all these questions become part of a customer signature that can be used to improve marketing efforts by, for instance, printing appropriate coupons.
The data for the Netflix recommendation system contest is a good example of narrow data that can be widened to provide both a movie signature and a subscriber signature. The original data has very few fields. Every movie has a title and a release date. Other than that, we have very little direct information. We are not told the genre of film, the running time, the director, the country of origin, the cast, or anything else. Of course, it would be possible to look those things up, but the point of this essay is that there is much to be learned from the data we do have, which consists of ratings.
The rating data has four columns: The Movie ID, the Customer ID, the rating (an integer from 1 to 5 with 5 being “loved it.”), and the date the rating was made. Everything explored in this essay is derived from those four columns.
The exploration process involves asking a lot of questions. Often, the answer to one question suggests several more questions.
How many movies are there? 17,770.
How many raters are there? 480,189.
How many ratings are there? 100,480,507.
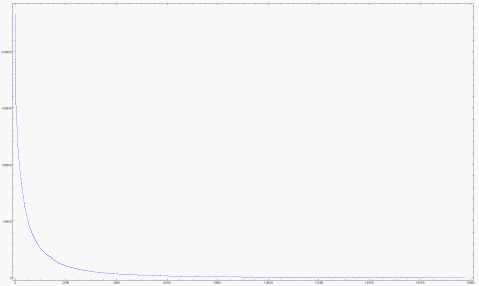
How are the ratintgs distributed?
 Overall distribution of ratings
Overall distribution of ratings
When is the earliest rating? 11 November 1999.
When is the latest rating? 31 December 2005.
What are the top ten most often rated movies? What are the ten least often rated movies?
What are the ten least often rated movies? Mobsters and Mormons
Mobsters and Mormons, the least often rated movie has been rated by only 3 viewers. It is one of two movies with raters in the single digits.
Land Before Time IV is the other.
What is the most loved movie?Lord of the Rings: The Return of the King: Extended Edition with an average rating of 4.7233.
What is the most disliked movie?Avia Vampire Hunter with an average rating of 1.2879. This movie did not get a single 4 or 5 from any of the 132 people who rated it. The reviewers’ comments on the Netflix site are amusing: "Do you love the acting and plot of porn, but can't stand all the sex and nakedness, well then, this is the movie for you!”
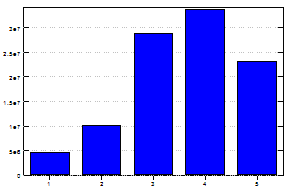
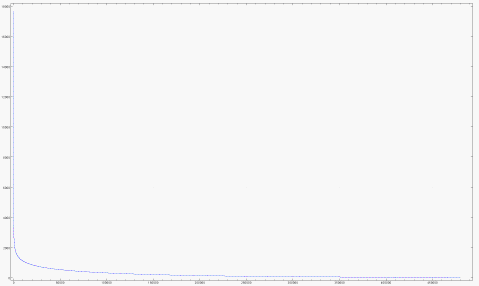
How many movies account for most of the ratings?
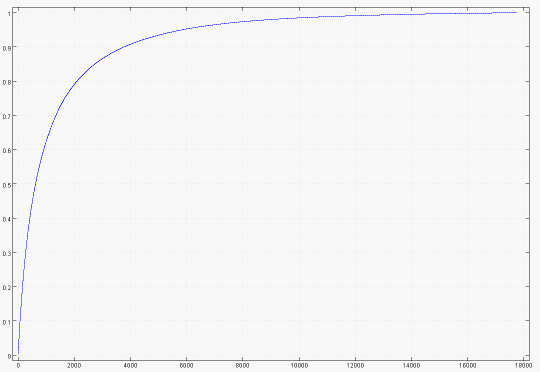
Cumulative proportion of raters accounted for by the most popular movies
The top 616 movies account for 50% of the ratings. The top 2,000 movies account for 80% or the ratings and the top 4,000 for 90%.
 <--This is how my scores are distributed.
<--This is how my scores are distributed.