If I want to test the effect of return of investment on a mail/ no mail sample, however, I cannot use a parametric test since the distribution of dollar amounts do not follow a normal distribution. What non-parametric test could I use that would give me something similar to a hypothesis test of two samples?
Recently, we received an email with the question above. Since it was addressed to [email protected], it seems quite reasonable to answer it here.
First, I need to note that Michael and I are not statisticians. We don't even play one on TV (hmm, that's an interesting idea). However, we have gleaned some knowledge of statistics over the years, much from friends and colleagues who are respected statisticians.
Second, the question I am going to answer is the following: Assume that we do a test, with a test group and a control group. What we want to measure is whether the average dollars per customer is significantly different for the test group as compared to the control group. The challenge is that the dollar amounts themselve do not follow a known distribution, or the distribution is known not to be a normal distribution. For instance, we might only have two products, one that costs $10 and one that costs $100.
The reason that I'm restating the problem is because a term such as ROI (return on investment) gets thrown around a lot. In some cases, it could mean the current value of discounted future cash flows. Here, though, I think it simply means the dollar amount that customers spend (or invest, or donate, or whatever depending on the particular business).
The overall approach is that we want to measure the average and standard error for each of the groups. Then, we'll apply a simple "standard error" of the difference to see if the difference is consistently positive or negative. This is a very typical use of a z-score. And, it is a topic that I discuss in more detail in Chapter 3 of my book "". In fact, the example here is slightly modified from the example in the book.
A good place to start is the Central Limit Theorem. This is a fundamental theorem for statistics. Assume that I have a population of things -- such as customers who are going to spend money in response to a marketing campaign. Assume that I take a sample of these customers and measure an average over the sample. Well, as I take more an more samples, the distribution of the averages follows a normal distribution regardless of the original distribution of values. (This is a slight oversimplification of the Central Limit Theorem, but it captures the important ideas.)
In addition, I can measure the relationship between the characteristics of the overall population and the characteristics of the sample:
(1) The average of the sample is as good an approximation as any of the average of the overall population.
(2) The standard error on the average of the sample is the standard deviation of the overall population divided by the square root of the size of the sample. Alternatively, we can phrase this in terms of variance: the variance of the sample average is the variance of the population average divided by the size of the sample.
Well, we are close. We know the average of each sample, because we can measure the average. If we knew the standard deviation of the overall population, then we could get the standard error for each group. Then, we'd know the standard error and we would be done. Well, it turns out that:
(3) The standard deviation of the sample is as good an approximation as any for the standard deviation of the population. This is convenient!
Let's assume that we have the following scenario.
Our test group has 17,839 customers, and the overall average purchase is $85.48. The control group has 53,537 customers, and the average purchase is $70.14. Is this statistically different?
We need some additional information, namely the standard deviation for each group. For the test group, the standard deviation is $197.23. For the control group, it is $196.67.
The standard error for the two groups is then $197.23/sqrt(17,839) and $196.67/sqrt(53,537), which comes to $1.48 and $0.85, respectively.
So, now the question is: is the difference of the means ($85.48 - $70.14 = $15.34) significantly different from zero. We need another formula from statistics to calculate the standard error of the difference. This formula says that the standard error is the square root of the sums of the squares of standard errors. So the value is $1.71 = sqrt(0.85^2 + 1.48^2).
And we have arrived at a place where we can use the z-score. The difference of $15.34 is about 9 standard deviations from 0 (that is, 9*1.71 is about 15.34). It is highly, highly, highly unlikely that the difference includes 0, so we can say that the test group is significantly better than the control group.
In short, we can apply the concepts of normal distributions, even to calculations on dollar amounts. We do need to be careful and pay attention to what we are doing, but the Central Limit Theorem makes this possible. If you are interested in this subject, I do strongly recommend Data Analysis Using SQL and Excel, particularly Chapter 3.
--gordon
Thursday, May 1, 2008
Monday, April 21, 2008
Using SET with Unique to Join Tables in SAS Data Steps
Recently, I have had to write a bunch of SAS code for one of our clients. Although I strive to do as much as possible using proc sql, there are some things that just require a data step. Alas.
When using the data step, I wish I were able call a query directly:
However, this is not possible.
A SAS programmer might point out that there are two easy work-arounds. First, you can simply call the query and save it as a SAS data set. Alternatively, you can define a view and access the view from the data step.
I do not like either of these solutions. One reason why I like SQL is that I can combine many different parts of a solution into a single SQL statement -- my SQL queries usually have lots of subqueries. Another reason I like SQL is it reduces the need for clutter -- intermediate files/tables/data sets -- which need to be named and tracked and managed and eventually deleted. I ran out of clever names for such things about fifteen years ago and much prefer having the database do the dirty work of tracking such things. Perhaps this is why I wrote a book on using SQL for data analysis.
So, I give up on the SQL syntax, but I still want to be able to do similar processing. The data step does make it possible to do joins, using a syntax that is almost intuitive (at least for data step code). The advertised syntax looks like:
This example is highly misleading! (So look below for a better version.) But, before explaining the problems and the solution, let me explain how the code works.
The first statement is a proc sql statement that builds an index on the lookup data set using the lookup key column. Real SAS programmers might prefer proc datasets, but I'm not a real SAS programmer. They do the same thing.
The second statement is the data step. The key part of the data step is the second set statement which uses the key= keyword. This keyword says to look up the corresponding value in another data set and fetch the first row where the values match. The "key" itself is an index, which is why I created the index first.
The keep part of the statement is just for efficiency's sake. This says to only keep the two variables that I want, the lookup key (which is needed for the index) and the lookup value. There may be another two hundred columns in the lookup table (er, data set), but these are the only ones that I want.
This basic example is quite deceptive. Indexes in SAS are a lot like indexes in databases. They are both called indexes and both give fast access to rows in a table, based on values in one or more columns. Both can be created in SQL.
However, they are not the same. The above syntax does work under some circumstances, such as when all the lookup keys are in the lookup table and when no two rows in a row in the master table have the same key (or some strange condition like that). Most importantly, I've found that the syntax seems to work on small test data but not on larger sets. This is a most nefarious type of difference. And, there are no warnings or errors.
The problem is that SAS indexes allow duplicates but treat indexes with duplicate keys differently from indexes with unique keys. Even worse, SAS determines this by how the index is created, not by the context. And for me (the database guy) the most frustrating thing is that the default is for the strange behavior instead of the nice clean behavior I'm expecting. I freely admit a bias here.
So we have to explicitly say that the index has no duplicates. In addition, SAS does not have reasonable behavior when there is no match. "Reasonable" behavior would be to set the lookup value to missing and to continue dutifully processing data. Instead, SAS generates an error and puts garbage in the lookup value.
The important change the presence of the unique signifier in both the create index statement and in the set statement. I have found that having it in one place is not sufficient, even when the index actually has no duplicates.
The error handling also tro ubles me. Strange functions called "iorc" are bad enough, even without being preceding by an underscore. Accessing global symbols such as _ERROR should be a sign that something extraordinary is going on. But nothing unusual is happening; the code is just taking into account the fact that the key is not in the lookup table.
In the end, I can use the data step to mimic SQL joins, including left outer joins (by taking into account, by using appropriate indexes and keys. Although I don't particularly like the syntax, I do find this capability very, very useful. The data step I referred to at the beginning of this post has eleven such lookups, and many of the lookup tables have hundreds of thousands or millions of rows.
--gordon
When using the data step, I wish I were able call a query directly:
data whereever;
....set (SELECT beautiful things using SQL syntax);
....and so on with the SAS code
However, this is not possible.
A SAS programmer might point out that there are two easy work-arounds. First, you can simply call the query and save it as a SAS data set. Alternatively, you can define a view and access the view from the data step.
I do not like either of these solutions. One reason why I like SQL is that I can combine many different parts of a solution into a single SQL statement -- my SQL queries usually have lots of subqueries. Another reason I like SQL is it reduces the need for clutter -- intermediate files/tables/data sets -- which need to be named and tracked and managed and eventually deleted. I ran out of clever names for such things about fifteen years ago and much prefer having the database do the dirty work of tracking such things. Perhaps this is why I wrote a book on using SQL for data analysis.
So, I give up on the SQL syntax, but I still want to be able to do similar processing. The data step does make it possible to do joins, using a syntax that is almost intuitive (at least for data step code). The advertised syntax looks like:
proc sql;
....create index lookupkey on lookup;
data whereever;
....set master;
....set lookup (keep=lookupkey lookupvalue) key=lookupkey;
....and so on with the SAS code
This example is highly misleading! (So look below for a better version.) But, before explaining the problems and the solution, let me explain how the code works.
The first statement is a proc sql statement that builds an index on the lookup data set using the lookup key column. Real SAS programmers might prefer proc datasets, but I'm not a real SAS programmer. They do the same thing.
The second statement is the data step. The key part of the data step is the second set statement which uses the key= keyword. This keyword says to look up the corresponding value in another data set and fetch the first row where the values match. The "key" itself is an index, which is why I created the index first.
The keep part of the statement is just for efficiency's sake. This says to only keep the two variables that I want, the lookup key (which is needed for the index) and the lookup value. There may be another two hundred columns in the lookup table (er, data set), but these are the only ones that I want.
This basic example is quite deceptive. Indexes in SAS are a lot like indexes in databases. They are both called indexes and both give fast access to rows in a table, based on values in one or more columns. Both can be created in SQL.
However, they are not the same. The above syntax does work under some circumstances, such as when all the lookup keys are in the lookup table and when no two rows in a row in the master table have the same key (or some strange condition like that). Most importantly, I've found that the syntax seems to work on small test data but not on larger sets. This is a most nefarious type of difference. And, there are no warnings or errors.
The problem is that SAS indexes allow duplicates but treat indexes with duplicate keys differently from indexes with unique keys. Even worse, SAS determines this by how the index is created, not by the context. And for me (the database guy) the most frustrating thing is that the default is for the strange behavior instead of the nice clean behavior I'm expecting. I freely admit a bias here.
So we have to explicitly say that the index has no duplicates. In addition, SAS does not have reasonable behavior when there is no match. "Reasonable" behavior would be to set the lookup value to missing and to continue dutifully processing data. Instead, SAS generates an error and puts garbage in the lookup value.
proc sql;
....create unique index lookupkey on lookup;
data whereever;
....set master;
....set lookup (keep=lookupkey lookupvalue) key=lookupkey/unique;
....if (_iorc_ = %sysrc(_dsenom)) then do;
........_ERROR_ = 0;
........lookupvalue = .;
....end;
....and so on with the SAS code
The important change the presence of the unique signifier in both the create index statement and in the set statement. I have found that having it in one place is not sufficient, even when the index actually has no duplicates.
The error handling also tro ubles me. Strange functions called "iorc" are bad enough, even without being preceding by an underscore. Accessing global symbols such as _ERROR should be a sign that something extraordinary is going on. But nothing unusual is happening; the code is just taking into account the fact that the key is not in the lookup table.
In the end, I can use the data step to mimic SQL joins, including left outer joins (by taking into account, by using appropriate indexes and keys. Although I don't particularly like the syntax, I do find this capability very, very useful. The data step I referred to at the beginning of this post has eleven such lookups, and many of the lookup tables have hundreds of thousands or millions of rows.
--gordon
Saturday, April 12, 2008
Using validation data in Enterprise Miner
Dear Sir/Madam,
I am a lecturer at De Montfort University in the UK and teach modules on
Data Mining at final year BSc and MSc level. For both of these we use the
Berry & Linoff Data Mining book. I have a couple of questions regarding SAS that I've been unable to find the answer to and I wondered if you could point in the direction of a source of info where I could find the answers. They are to do with partitioning data in SAS EM and how the different data sets are used. In the Help from SAS EM I see that it says the validation set is used in regression "to choose a final subset of predictors from all the subsets computed during stepwise regression" - so is the validation set not used in regression otherwise (e.g. in forward deletion and backward deletion)?
Also I'm not sure where we see evidence of the test set being used in any of the models I've developed (NNs, Decision Trees, Regression). I presume the lift charts are based on the actual model (resulting from the training and validation data sets) though I noticed if I only had a training and a validation data set (i.e. no test set) the lift chart gave a worse model.
I hope you don't mind me asking these questions - My various books and the help don't seem to explain fully but I know it must be documented somewhere.
best wishes, Jenny Carter
Dr. Jenny Carter
Dept. of Computing
De Montfort University
The Gateway
Leicester
Hi Jenny,
I'd like to take this opportunity to go beyond your actual question about SAS Enterprise Miner to make a general comment on the use of validation sets for variable selection in regression models and to guard against overfitting in decision tree and neural network models.
Historically, statistics grew up in a world of small datasets. As a result, many statistical tools reuse the same data to fit candidate models as to evaluate and select them. In a data mining context, we assume that there is plenty of data so there is no need to reuse the training data. The problem with using the training data to evaluate a model is that overfitting may go undetected. The best model is not the one that best describes the training data; it is the one that best generalizes to new datasets. That is what the validation is for. The details of how Enterprise Miner accomplishes this vary with the type of model. In no case does the test set get used for either fitting the model or selecting from among candidate models. Its purpose is to allow you to see how your model will do on data that was not involved in the model building or selection process.
Regression Models
When you use any of the model selection methods (Forward, Stepwise, Backward), you also get to select a method for evaluating the candidate models formed from different combinations of explanatory variables. Most of the choices make no use of the validation data. Akaike's Information Criterion and Schwarz's Bayesian Criterion both add a penalty term for the number of effects in the model to a function of the error sum of squares. This penalty term is meant to compensate for the fact that additional model complexity appears to lower the error on the training data even when the model is not actually improving. When you choose Validation Error as the selection criterion, you get the model that minimizes error on the validation set. That is our recommended setting. You must also take care to set Use Selection Default to No in the Model Selection portion of the property sheet of Enterprise Miner will ignore the rest of your settings.
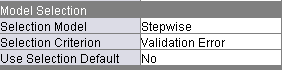
When a training set, validation set, and test set are all present, Enterprise Miner will report statistics such as the root mean squared error for all three sets. The error on the test set, which is not used to fit models nor to select candidate models, is the best predictor of performance on unseen data.
Decision Trees
With decision trees, the validation set is used to select a subtree of the tree grown using the training set. This process is called "pruning." Pruning helps prevent overfitting. Some splits which have a sufficiently high worth (chai-square value) on the training data to enter the initial tree, fail to improve the error rate of the tree when applied to the validation data. This is especially likely to happen when small leaf sizes are allowed. By default, if a validation set is present, Enterprise Miner will use it for subtree selection.
Neural Networks
Training a neural network is an iterative process. Each training iteration adjusts the weights associated with each network connection. As training proceeds, the network becomes better and better at "predicting" the training data. By the time training stops, the model is almost certainly overfit. Each set of weights is a candidate model. The selected model is the one that minimizes error on the validation set. In the chart shown below, after 20 iterations of training the error on the training set is still declining, but the best model was reached after on 3 training iterations.

Tuesday, April 8, 2008
Databases, MapReduce, and Disks
I just came across an interesting blog posting by Tom White entitled "Disks Have Become Tapes". This is an interesting posting, but it makes the following claim: relational databases are limited by the seek speed of disks whereas MapReduce-based methods take advantage of the streaming capabilities of disks. Hence, MapReduce is better than RDBMS for various types of processing.
Once again, I read a comment in a blog that seems misguided and gives inaccurate information. My guess is that people learn relational databases from the update/insert perspective and don't understand complex query processing. Alas. I do recommend my book for such folks. Relational databases can take advantage of high-throughput disks.
Of course, the problem is not new. Tom White quotes David DeWitt quoting Jim Gray saying "Disks are the new tapes" (here). And the numbers are impressive. It takes longer to read a high capacity disk now than it did twenty years ago, because capacity has increased much faster than transfer rates. As for random seeks on the disk, let's not go there. Seek times have hardly improved at all over this time period. Seeking on a disk is like going to Australia in a canoe -- the canoe works well enough to cross a river, so why not an ocean? And, as we all know, RDBMSs use a lot of seeks for queries so they cannot take advantage of modern disks. MapReduce to the rescue!
Wait, is that common wisdom really true?
It is true that for updating or fetching a single row, an RDBMS does use disk seeks to get there (especially if there is an index). However, this is much faster than the alternative of streaming through the whole table -- even on a fancy, multi-cheap processor MapReduce systems connected to zillions of inexpensive disks.
On a complex query, the situation is a bit more favorable to the RDBMS for several reasons. First, large analytic queries typically read entire tables (or partitions of tables). They do not "take advantage" of indexing, since they read all rows using full table scans.
However, database engines do not read rows. They read pages. Between the query processor and the data is the page manager. Or, as T. S. Elliott wrote in his poem "The Hollow Men" [on an entirely different topic]:
In this case, the shadow is the page manager, a very important part but often overlooked component of a database management system.
Table scans read the pages assigned to a table. So, query performance is based on a balance of disk performance (both throughput and latency) and page size. For a database used for analytics, use a big page size. 4k is way small . . . 128k or even 1Mbyte could be very reasonable (and I have seen systems with even larger page sizes). Also, remember to stuff the pages full. There is no reason to partially fill pages unless the table has updates (which is superfluous for most data warehouse tables).
Databases do a lot of things to improve performance. Probably the most important boost is accidental. Large database tables are typically loaded in bulk, say once-per-day. As a result, the pages are quite likely to be allocated sequentially. Voila! In such cases, the seek time from one page to the next is minimal.
But, databases are smarter than that. The second boost is pre-fetching pages that are likely to be needed. Even a not-so-smart database engine can realize when it is doing a full table scan. The page manager can seek to the next page at the same time that the processor is processing data in memory. That is, the CPU is working, while the page manager spends its time waiting for new pages to load. Although the page manager is waiting, the CPU is quite busy processing other data, so there is no effective wait time.
This overlap between CPU cycles and disk is very important for database performance on large queries. And you can see it on a database machine. In a well-balanced system, the CPUs are often quite busy on a large query and the disks are less busy.
Modern RDBMS have a third capability with respect to complex queries. Much of the work is likely to take place in temporary tables. The page manager would often store these on sequential pages, and they would be optimized for sequential access. In addition, temporary tables only store the columns that they need.
In short, databases optimize their disk access in several ways. They take advantage of high-throughput disks by:
The advantage and disadvantage of the MapReduce approach is that it leaves such optimizations in the hands of the operating system and the programmer. Fortunately, modern computer languages are smart with respect to sequential file I/O, so reading some records and then processing them would normally be optimized.
Of course, a programmer can disrupt this by writing temporary or output files to the same disk system being used to read data. Well, actually, disks are also getting smarter. With multiple platters and multiple read heads, modern disks can support multiple seeks to different areas.
A bigger problem arises with complex algorithms. MapReduce does not provide built-in support for joining large tables. Nor even for joining smaller tables. A nested loop join in MapReduce code could kill the performance of a query. An RDBMS might implement the same join using hash tables that gracefully overflow memory, should that be necessary. An exciting development in a programmer's life is when a hash table in memory gets too big and he or she learns about operating system page faults, a concern that the database engine takes care of by itself.
As I've mentioned before, RDBMS versus MapReduce is almost a religious battle. MapReduce has capabilities that RDBMSs do not have, and not only because programming languages are more expressive than SQL. The paradigm is strong and capable for certain tasks.
On the other hand, SQL is a comparatively easy language to learn (I mean compared to programming for MapReduce) and relational databases engines often have decades of experience built into them, for partitioning data, choosing join and aggregation algorithms, building temporary tables, keeping processors busy and disks spinning, and so on. In particular, RDBMSs do know a trick or two to optimize disk performance and take advantage of modern highish-latency higher-throughput disks.
--gordon
Once again, I read a comment in a blog that seems misguided and gives inaccurate information. My guess is that people learn relational databases from the update/insert perspective and don't understand complex query processing. Alas. I do recommend my book for such folks. Relational databases can take advantage of high-throughput disks.
Of course, the problem is not new. Tom White quotes David DeWitt quoting Jim Gray saying "Disks are the new tapes" (here). And the numbers are impressive. It takes longer to read a high capacity disk now than it did twenty years ago, because capacity has increased much faster than transfer rates. As for random seeks on the disk, let's not go there. Seek times have hardly improved at all over this time period. Seeking on a disk is like going to Australia in a canoe -- the canoe works well enough to cross a river, so why not an ocean? And, as we all know, RDBMSs use a lot of seeks for queries so they cannot take advantage of modern disks. MapReduce to the rescue!
Wait, is that common wisdom really true?
It is true that for updating or fetching a single row, an RDBMS does use disk seeks to get there (especially if there is an index). However, this is much faster than the alternative of streaming through the whole table -- even on a fancy, multi-cheap processor MapReduce systems connected to zillions of inexpensive disks.
On a complex query, the situation is a bit more favorable to the RDBMS for several reasons. First, large analytic queries typically read entire tables (or partitions of tables). They do not "take advantage" of indexing, since they read all rows using full table scans.
However, database engines do not read rows. They read pages. Between the query processor and the data is the page manager. Or, as T. S. Elliott wrote in his poem "The Hollow Men" [on an entirely different topic]:
Between the idea
And the reality
Between the motion
And the act
Falls the shadow
In this case, the shadow is the page manager, a very important part but often overlooked component of a database management system.
Table scans read the pages assigned to a table. So, query performance is based on a balance of disk performance (both throughput and latency) and page size. For a database used for analytics, use a big page size. 4k is way small . . . 128k or even 1Mbyte could be very reasonable (and I have seen systems with even larger page sizes). Also, remember to stuff the pages full. There is no reason to partially fill pages unless the table has updates (which is superfluous for most data warehouse tables).
Databases do a lot of things to improve performance. Probably the most important boost is accidental. Large database tables are typically loaded in bulk, say once-per-day. As a result, the pages are quite likely to be allocated sequentially. Voila! In such cases, the seek time from one page to the next is minimal.
But, databases are smarter than that. The second boost is pre-fetching pages that are likely to be needed. Even a not-so-smart database engine can realize when it is doing a full table scan. The page manager can seek to the next page at the same time that the processor is processing data in memory. That is, the CPU is working, while the page manager spends its time waiting for new pages to load. Although the page manager is waiting, the CPU is quite busy processing other data, so there is no effective wait time.
This overlap between CPU cycles and disk is very important for database performance on large queries. And you can see it on a database machine. In a well-balanced system, the CPUs are often quite busy on a large query and the disks are less busy.
Modern RDBMS have a third capability with respect to complex queries. Much of the work is likely to take place in temporary tables. The page manager would often store these on sequential pages, and they would be optimized for sequential access. In addition, temporary tables only store the columns that they need.
In short, databases optimize their disk access in several ways. They take advantage of high-throughput disks by:
- using large page sizes to reduce the impact of latency;
- storing large databases on sequential pages;
- prefetching pages while the processor works on data already in memory;
- efficiently storing temporary tables.
The advantage and disadvantage of the MapReduce approach is that it leaves such optimizations in the hands of the operating system and the programmer. Fortunately, modern computer languages are smart with respect to sequential file I/O, so reading some records and then processing them would normally be optimized.
Of course, a programmer can disrupt this by writing temporary or output files to the same disk system being used to read data. Well, actually, disks are also getting smarter. With multiple platters and multiple read heads, modern disks can support multiple seeks to different areas.
A bigger problem arises with complex algorithms. MapReduce does not provide built-in support for joining large tables. Nor even for joining smaller tables. A nested loop join in MapReduce code could kill the performance of a query. An RDBMS might implement the same join using hash tables that gracefully overflow memory, should that be necessary. An exciting development in a programmer's life is when a hash table in memory gets too big and he or she learns about operating system page faults, a concern that the database engine takes care of by itself.
As I've mentioned before, RDBMS versus MapReduce is almost a religious battle. MapReduce has capabilities that RDBMSs do not have, and not only because programming languages are more expressive than SQL. The paradigm is strong and capable for certain tasks.
On the other hand, SQL is a comparatively easy language to learn (I mean compared to programming for MapReduce) and relational databases engines often have decades of experience built into them, for partitioning data, choosing join and aggregation algorithms, building temporary tables, keeping processors busy and disks spinning, and so on. In particular, RDBMSs do know a trick or two to optimize disk performance and take advantage of modern highish-latency higher-throughput disks.
--gordon
Sunday, March 16, 2008
Getting an Iphone
[This posting has nothing to do with data mining.]
Last week, a friend gave me an iPhone for my birthday. Before that, I had admired the iPhone at a distance as several of my friends and colleagues used theirs. I should also admit that I'm something of a Luddite. Technology for technology sake does not appeal to me; it often just means additional work. Having spent the weekend setting up and getting used to the phone, the fear is confirmed. However, the end result is worth it.
The first step in using the iPhone is getting service, which is as simple as downloading iTunes, hooking up the phone, and going through a few menus. Of course, there are a few complications. The most recent version of iTunes does not support the version of Windows I have on my laptop. Remember the Luddite in me, causing me to be resistant to a much needed laptop upgrade.
That issue was easily resolved by moving to another computer. The second fear was porting my number from T-Mobile to AT&T. This turned out to be a non-issue. Just click a box on one of the screens, put in my former number (and look up my account number) and the phone companies do the rest.
So once you have an iPhone in place, then expect to spend several hours learning how to operate it. After getting lost in the interface, perhaps somewhere in contacts, I painfully learned that there is only one way to get back to the home page. I'm pretty sure I tried all other combinations by hitting options on the screen. However, there is actually a little button on the bottom of the screen -- a real button -- that brings back the home page. Well, at least they got rid of all the keys with numbers on them.
The next step is sync'ing the iPhone to your life. This is simplest if your mail, calendar, and contacts are all handled in Outlook or Yahoo!. Somehow, Apple is not compatible with Google. Alas. So, bringing in my contacts from Google meant:
(1) Spending an hour or two cleaning up my contact list in Google, and adding telephone numbers from my old phone. Since the iPhone has email capabilities, I really wanted to bring in email addresses as well as phone numbers.
(2) Exporting the Google contacts into a text file.
(3) Very importantly: renaming the "Name" column in the first line to "First Name". Google has only one name field, but Yahoo (and the iPhone) want two fields.
(4) Uploading my contacts into my Yahoo account.
(5) Sync'ing the iPhone up with my Yahoo account.
Okay, I can accept that some global politics keeps the iPhone from talking directly to Google. But, why do I need to connect to the computer to do the sync? Why can't I do it over the web wirelessly?
Okay, that's the contacts, and we'll see how it works.
The calendar is more difficult. For that, I just use Safari -- the iPhone browser -- to go to Google calendar. This seems to work well enough. However, even this can be complicated because I have two Google accounts -- one for email ([email protected]) and one for all my Data Miners related stuff ([email protected]). The calendar is on the latter. I seem to have gotten a working version up in Safari, by going through the calendar page.
Note that I did not use Google's suggestion of pasting in the URL for my private calendar. I found that the functionality when I do this is not complete. It is hard to add in events.
And this brings up a subject about Safari. First, it is incredible what it can do on a small portable device. On the other hand, it is insane that I was unable to set up my AT&T account using Safari. Each time I went through the same routine. AT&T send me a temporary password. I went to the next screen, and filled in new passwords and answers to the security questions (somewhat painfully, one character at a time, but I was on a train at the time). After finishing, I would go to a validation screen, the validation would fail, and I would go back to the first page. The only thing that saed me was the training reaching Penn Station and the iPhone running out of battery power.
Once I got home, I did the same thing on my computer. And, it worked the first time.
I also noticed that certain forms do not work perfectly in Safari, such as the prompts for Google calendar. On the other hand, it was easy to go to web pages, add book marks, and put the pages on the home screen.
Fortunately, the email does not actually go through the Safari interface. This makes it easy to read email, because the application is customized. However, Safari would have some advantages. First, Safari rotates when the screen rotates, but the email doesn't (which is unfortunately because stubby fingers work better in horizontal mode). Also, only the most recent 50 emails are downloaded, so searching through history is not feasible. On the plus side, sending an email, still shows up in gmail.
Perhaps the most impressive feature of the phone are the maps. There is a home key on the map which tells you where you are. Very handy. We were watching the movie "The Water Horse". Within a minute, I could produce a map and satellite pictures of Loch Ness in Scotland, with all the zoom-in and zoom-out features. Followed close by is the ability to surf the web. And both of these are faster on a wide-area network, which I have.
I still haven't used the music or video, so there is more to learn. But the adventure seems worth it so far.
Last week, a friend gave me an iPhone for my birthday. Before that, I had admired the iPhone at a distance as several of my friends and colleagues used theirs. I should also admit that I'm something of a Luddite. Technology for technology sake does not appeal to me; it often just means additional work. Having spent the weekend setting up and getting used to the phone, the fear is confirmed. However, the end result is worth it.
The first step in using the iPhone is getting service, which is as simple as downloading iTunes, hooking up the phone, and going through a few menus. Of course, there are a few complications. The most recent version of iTunes does not support the version of Windows I have on my laptop. Remember the Luddite in me, causing me to be resistant to a much needed laptop upgrade.
That issue was easily resolved by moving to another computer. The second fear was porting my number from T-Mobile to AT&T. This turned out to be a non-issue. Just click a box on one of the screens, put in my former number (and look up my account number) and the phone companies do the rest.
So once you have an iPhone in place, then expect to spend several hours learning how to operate it. After getting lost in the interface, perhaps somewhere in contacts, I painfully learned that there is only one way to get back to the home page. I'm pretty sure I tried all other combinations by hitting options on the screen. However, there is actually a little button on the bottom of the screen -- a real button -- that brings back the home page. Well, at least they got rid of all the keys with numbers on them.
The next step is sync'ing the iPhone to your life. This is simplest if your mail, calendar, and contacts are all handled in Outlook or Yahoo!. Somehow, Apple is not compatible with Google. Alas. So, bringing in my contacts from Google meant:
(1) Spending an hour or two cleaning up my contact list in Google, and adding telephone numbers from my old phone. Since the iPhone has email capabilities, I really wanted to bring in email addresses as well as phone numbers.
(2) Exporting the Google contacts into a text file.
(3) Very importantly: renaming the "Name" column in the first line to "First Name". Google has only one name field, but Yahoo (and the iPhone) want two fields.
(4) Uploading my contacts into my Yahoo account.
(5) Sync'ing the iPhone up with my Yahoo account.
Okay, I can accept that some global politics keeps the iPhone from talking directly to Google. But, why do I need to connect to the computer to do the sync? Why can't I do it over the web wirelessly?
Okay, that's the contacts, and we'll see how it works.
The calendar is more difficult. For that, I just use Safari -- the iPhone browser -- to go to Google calendar. This seems to work well enough. However, even this can be complicated because I have two Google accounts -- one for email ([email protected]) and one for all my Data Miners related stuff ([email protected]). The calendar is on the latter. I seem to have gotten a working version up in Safari, by going through the calendar page.
Note that I did not use Google's suggestion of pasting in the URL for my private calendar. I found that the functionality when I do this is not complete. It is hard to add in events.
And this brings up a subject about Safari. First, it is incredible what it can do on a small portable device. On the other hand, it is insane that I was unable to set up my AT&T account using Safari. Each time I went through the same routine. AT&T send me a temporary password. I went to the next screen, and filled in new passwords and answers to the security questions (somewhat painfully, one character at a time, but I was on a train at the time). After finishing, I would go to a validation screen, the validation would fail, and I would go back to the first page. The only thing that saed me was the training reaching Penn Station and the iPhone running out of battery power.
Once I got home, I did the same thing on my computer. And, it worked the first time.
I also noticed that certain forms do not work perfectly in Safari, such as the prompts for Google calendar. On the other hand, it was easy to go to web pages, add book marks, and put the pages on the home screen.
Fortunately, the email does not actually go through the Safari interface. This makes it easy to read email, because the application is customized. However, Safari would have some advantages. First, Safari rotates when the screen rotates, but the email doesn't (which is unfortunately because stubby fingers work better in horizontal mode). Also, only the most recent 50 emails are downloaded, so searching through history is not feasible. On the plus side, sending an email, still shows up in gmail.
Perhaps the most impressive feature of the phone are the maps. There is a home key on the map which tells you where you are. Very handy. We were watching the movie "The Water Horse". Within a minute, I could produce a map and satellite pictures of Loch Ness in Scotland, with all the zoom-in and zoom-out features. Followed close by is the ability to surf the web. And both of these are faster on a wide-area network, which I have.
I still haven't used the music or video, so there is more to learn. But the adventure seems worth it so far.
Wednesday, March 12, 2008
Data Mining Brings Down Governor Spitzer
When New York Governor Elliott Spitzer resigned earlier today the proximate cause was the revelation that he had spent thousands of dollars (maybe tens of thousands) on prostitutes. This hypocrisy on the part of the former NY Attorney General who is married with three teenage daughters, and a long record of prosecuting the wrongdoings of others made his continuation in office untenable.
But how was he caught? The answer is that the complicated financial transactions he made in an attempt to disguise his spending on prostitutes were flagged by fraud detection software that banks now use routinely to detect money laundering and other financial crimes. In a news report on NPR this morning, reporter Adam Davidson interviewed a representative from Actimize, an Israeli company that specializes in fraud detection and compliance software. The software scores every bank transaction with a number from 0 to 100 indicating the probability of fraud. The software takes into account attributes of the particular transaction, but also its relationship to other transaction (as when several small transactions with the same source and destination are used to disguise a large transaction), the relationship of account owners involved in the transaction, and attributes of the account owner such as credit score and, unfortunately for Governor Spitzer, whether or not the account owner is a "PEP" (politically exposed person). PEPs attract more scrutiny since they are often in a position to be bribed or engage in other corrupt practices.
Banks are required to report SARs (Suspicious Activity Reports) to FinCEN, the Treasury Department's financial crimes enforcement network. The reports--about a million of them in 2006--go into a database hosted at the IRS and teams of investigators around the country look into them. One such team, based in Long Island, looked into Sptizer's suspicious transactions and eventually discovered the connection to the prostitution ring.
Ironically, one of the reasons there are so many more SARs filed each year now than there were before 2001 is that in 2001, then New York Attorney General, Elliott Spitzer aggressively pursued wrong-doing at financial institutions and said they had to be aware of criminal activity conducted through their accounts. Apparently, the software banks installed to find transactions that criminal organizations are trying to hide from the IRS is also capable of finding transactions that Johns are trying to hide from their wives.
But how was he caught? The answer is that the complicated financial transactions he made in an attempt to disguise his spending on prostitutes were flagged by fraud detection software that banks now use routinely to detect money laundering and other financial crimes. In a news report on NPR this morning, reporter Adam Davidson interviewed a representative from Actimize, an Israeli company that specializes in fraud detection and compliance software. The software scores every bank transaction with a number from 0 to 100 indicating the probability of fraud. The software takes into account attributes of the particular transaction, but also its relationship to other transaction (as when several small transactions with the same source and destination are used to disguise a large transaction), the relationship of account owners involved in the transaction, and attributes of the account owner such as credit score and, unfortunately for Governor Spitzer, whether or not the account owner is a "PEP" (politically exposed person). PEPs attract more scrutiny since they are often in a position to be bribed or engage in other corrupt practices.
Banks are required to report SARs (Suspicious Activity Reports) to FinCEN, the Treasury Department's financial crimes enforcement network. The reports--about a million of them in 2006--go into a database hosted at the IRS and teams of investigators around the country look into them. One such team, based in Long Island, looked into Sptizer's suspicious transactions and eventually discovered the connection to the prostitution ring.
Ironically, one of the reasons there are so many more SARs filed each year now than there were before 2001 is that in 2001, then New York Attorney General, Elliott Spitzer aggressively pursued wrong-doing at financial institutions and said they had to be aware of criminal activity conducted through their accounts. Apparently, the software banks installed to find transactions that criminal organizations are trying to hide from the IRS is also capable of finding transactions that Johns are trying to hide from their wives.
Saturday, February 9, 2008
MapReduce and K-Means Clustering
Google offers slides and presentations on many research topics online including distributed systems. And one of these presentations discusses MapReduce in the context of clustering algorithms.
One of the claims made in this particular presentation is that "it can be necessary to send tons of data to each Mapper Node. Depending on your bandwidth and memory available, this could be impossible." This claim is false, which in turn removes much of the motivation for the alternative algorithm, which called "canopy clustering".
The K-Means Clustering Algorithm
There are many good introductions to k-means clustering available, including our book Data Mining Techniques for Marketing, Sales, and Customer Support. The Google presentation mentioned above provides a very brief introduction.
Let's review the k-means clustering algorithm. Given a data set where all the columns are numeric, the algorithm for k-means clustering is basically the following:
(1) Start with k cluster centers (chosen randomly or according to some specific procedure).
(2) Assign each row in the data to its nearest cluster center.
(3) Re-calculate the cluster centers as the "average" of the rows in (2).
(4) Repeat, until the cluster centers no longer change or some other stopping criterion has been met.
In the end, the k-means algorithm "colors" all the rows in the data set, so similar rows have the same color.
K-Means in a Parallel World
To run this algorithm, it seems, at first, as though all the rows assigned to each cluster in Step (2) need to be brought together to recalculate the cluster centers.
However, this is not true. K-Means clustering is an example of an embarrassingly parallel algorithm, meaning that that it is very well suited to parallel implementations. In fact, it is quite adaptable to both SQL and to MapReduce, with efficient algorithms. By "efficient", I mean that large amounts of data do not need to be sent around processors and that the processors have minimum amounts of communication. It is true that the entire data set does need to be read by the processors for each iteration of the algorithm, but each row only needs to be read by one processor.
A parallel version of the k-means algorithm was incorporated into the Darwin data mining package, developed by Thinking Machines Corporation in the early 1990s. I do not know if this was the first parallel implementation of the algorithm. Darwin was later purchased by Oracle, and became the basis for Oracle Data Mining.
How does the parallel version work? The data can be partitioned among multiple processors (or streams or threads). Each processor can read the previous iteration's cluster centers and assign the rows on the processor to clusters. Each processor then calculates new centers for its of data. Each actual cluster center (for the data across all processors) is then the weighted average of the centers on each processor.
In other words, the rows of data do not need to be combined globally. They can be combined locally, with the reduced set of results combined across all processors. In fact, MapReduce even contains a "combine" method for just this type of algorithm.
All that remains is figuring out how to handle the cluster center information. Let us postulate a shared file that has the centroids as calculated for each processor. This file contains:
There are two ways to do this in the MapReduce framework. The first uses map, combine, and reduce. The second only uses map and reduce.
K-Means Using Map, Combine, Reduce
Before begining, a file is created accessible to all processors that contains initial centers for all clusters. This file contains the cluster centers for each iteration.
The Map function reads this file to get the centers from the last finished iteration. It then reads the input rows (the data) and calculates the distance to each center. For each row, it produces an output pair with:
The Reduce function (and one of these is probably sufficient for this problem regardless of data size and the number of Maps) calcualtes the weighted average of its input. Its output should be written to a file, and contain:
K-Means Using Just Map and Reduce
Using just Map and Reduce, it is possible to do the same things. In this case, the Map and Combine functions described above are combined into a single function.
So, the Map function does the following:
K-Means Using SQL
Of course, one of my purposes in discussing MapReduce has been to understand whether and how it is more powerful than SQL. For fifteen years, databases have been the only data-parallel application readily available. The parallelism is hidden underneath the SQL language, so many people using SQL do not fully appreciate the power they are using.
An iteration of k-means looks like:
This code assumes the existence of functions or code for the AVERAGE() and DISTANCE() functions. These are placeholders for the correct functions. Also, it uses analytic functions. (If you are not familiar with these, I recommend my book Data Analysis Using SQL and Excel.)
The efficiency of the SQL code is determined, to a large extent, by the analytic function that ranks all the cluster centers. We hope that a powerful parallel engine will recognize that the data is all in one place, and hence that this function will be quite efficient.
A Final Note About K-Means Clustering
The K-Means clustering algorithm does require reading through all the data for each iteration through the algorithm. In general, it tends to converge rather quickly (tens of iterations), so this may not be an issue. Also, the I/O for reading the data can all be local I/O, rather than sending large amounts of data through the network.
For most purposes, if you are dealing with a really big dataset, you can sample it down to a fraction of its original size to get reasonable clusters. If you are not satisfied with this method, then sample the data, find the centers of the clusters, and then use these to initialize the centers for the overall data. This will probably reduce the number of iterations through the entire data to less than 10 (one pass for the sample, a handful for the final clustering).
When running the algorithm on very large amounts of data, numeric overflow is a very real issue. This is another reason why clustering locally, taking averages, and then taking the weighted average globally is beneficial -- and why doing sample is a good way to begin.
Also, before clustering, it is a good idea to standardize numeric variables (subtract the average and divide by the standard deviation).
--gordon
Check out my latest book Data Analysis Using SQL and Excel.
One of the claims made in this particular presentation is that "it can be necessary to send tons of data to each Mapper Node. Depending on your bandwidth and memory available, this could be impossible." This claim is false, which in turn removes much of the motivation for the alternative algorithm, which called "canopy clustering".
The K-Means Clustering Algorithm
There are many good introductions to k-means clustering available, including our book Data Mining Techniques for Marketing, Sales, and Customer Support. The Google presentation mentioned above provides a very brief introduction.
Let's review the k-means clustering algorithm. Given a data set where all the columns are numeric, the algorithm for k-means clustering is basically the following:
(1) Start with k cluster centers (chosen randomly or according to some specific procedure).
(2) Assign each row in the data to its nearest cluster center.
(3) Re-calculate the cluster centers as the "average" of the rows in (2).
(4) Repeat, until the cluster centers no longer change or some other stopping criterion has been met.
In the end, the k-means algorithm "colors" all the rows in the data set, so similar rows have the same color.
K-Means in a Parallel World
To run this algorithm, it seems, at first, as though all the rows assigned to each cluster in Step (2) need to be brought together to recalculate the cluster centers.
However, this is not true. K-Means clustering is an example of an embarrassingly parallel algorithm, meaning that that it is very well suited to parallel implementations. In fact, it is quite adaptable to both SQL and to MapReduce, with efficient algorithms. By "efficient", I mean that large amounts of data do not need to be sent around processors and that the processors have minimum amounts of communication. It is true that the entire data set does need to be read by the processors for each iteration of the algorithm, but each row only needs to be read by one processor.
A parallel version of the k-means algorithm was incorporated into the Darwin data mining package, developed by Thinking Machines Corporation in the early 1990s. I do not know if this was the first parallel implementation of the algorithm. Darwin was later purchased by Oracle, and became the basis for Oracle Data Mining.
How does the parallel version work? The data can be partitioned among multiple processors (or streams or threads). Each processor can read the previous iteration's cluster centers and assign the rows on the processor to clusters. Each processor then calculates new centers for its of data. Each actual cluster center (for the data across all processors) is then the weighted average of the centers on each processor.
In other words, the rows of data do not need to be combined globally. They can be combined locally, with the reduced set of results combined across all processors. In fact, MapReduce even contains a "combine" method for just this type of algorithm.
All that remains is figuring out how to handle the cluster center information. Let us postulate a shared file that has the centroids as calculated for each processor. This file contains:
- The iteration number.
- The cluster id.
- The cluster coordinates.
- The number of rows assigned to the cluster.
There are two ways to do this in the MapReduce framework. The first uses map, combine, and reduce. The second only uses map and reduce.
K-Means Using Map, Combine, Reduce
Before begining, a file is created accessible to all processors that contains initial centers for all clusters. This file contains the cluster centers for each iteration.
The Map function reads this file to get the centers from the last finished iteration. It then reads the input rows (the data) and calculates the distance to each center. For each row, it produces an output pair with:
- key -- cluster id;
- value -- coordinates of row.
- key is cluster
- value is number of records and average values of the coordinates.
The Reduce function (and one of these is probably sufficient for this problem regardless of data size and the number of Maps) calcualtes the weighted average of its input. Its output should be written to a file, and contain:
- the iteration number;
- the cluster id;
- the cluster center coordinates;
- the size of the cluster.
K-Means Using Just Map and Reduce
Using just Map and Reduce, it is possible to do the same things. In this case, the Map and Combine functions described above are combined into a single function.
So, the Map function does the following:
- Initializes itself with the cluster centers from the previous iteration;
- Keeps information about each cluster in memory. This information is the total number of records assigned to the cluster in the processor and the total of each coordinate.
- For each record, it updates the information in memory.
- It then outputs the key-value pairs for the Combine function described above.
K-Means Using SQL
Of course, one of my purposes in discussing MapReduce has been to understand whether and how it is more powerful than SQL. For fifteen years, databases have been the only data-parallel application readily available. The parallelism is hidden underneath the SQL language, so many people using SQL do not fully appreciate the power they are using.
An iteration of k-means looks like:
SELECT @iteration+1, cluster_id,
.......AVERAGE(d.data) as center
FROM (SELECT d.data, cc.cluster_id,
.............ROW_NUMBER() OVER (PARTITION BY d.data
................................ORDER BY DISTANCE(d.data, cc.center) as ranking
......FROM data d CROSS JOIN
.....(SELECT *
......FROM cluster_centers cc
......WHERE iteration = @iteration) cc
.....) a
WHERE ranking = 1
GROUP BY cluster_id
This code assumes the existence of functions or code for the AVERAGE() and DISTANCE() functions. These are placeholders for the correct functions. Also, it uses analytic functions. (If you are not familiar with these, I recommend my book Data Analysis Using SQL and Excel.)
The efficiency of the SQL code is determined, to a large extent, by the analytic function that ranks all the cluster centers. We hope that a powerful parallel engine will recognize that the data is all in one place, and hence that this function will be quite efficient.
A Final Note About K-Means Clustering
The K-Means clustering algorithm does require reading through all the data for each iteration through the algorithm. In general, it tends to converge rather quickly (tens of iterations), so this may not be an issue. Also, the I/O for reading the data can all be local I/O, rather than sending large amounts of data through the network.
For most purposes, if you are dealing with a really big dataset, you can sample it down to a fraction of its original size to get reasonable clusters. If you are not satisfied with this method, then sample the data, find the centers of the clusters, and then use these to initialize the centers for the overall data. This will probably reduce the number of iterations through the entire data to less than 10 (one pass for the sample, a handful for the final clustering).
When running the algorithm on very large amounts of data, numeric overflow is a very real issue. This is another reason why clustering locally, taking averages, and then taking the weighted average globally is beneficial -- and why doing sample is a good way to begin.
Also, before clustering, it is a good idea to standardize numeric variables (subtract the average and divide by the standard deviation).
--gordon
Check out my latest book Data Analysis Using SQL and Excel.
Subscribe to:
Posts (Atom)


