On Tuesday, May 24 at 1:00pm Eastern Daylight Time, I will be presenting a webcast on behalf of JMP, a visual data exploration and mining tool. The main theme of the talk is that companies tend to manage to metrics, so it is very important that the metrics are well-chosen. I will illustrate this with a small case study from the world on on-line retailing recommendations. A secondary theme is the importance of careful data exploration in preparation for modeling--a task JMP is well-suited to.
-Michael
Register.
Sunday, May 22, 2011
Tuesday, May 17, 2011
Michael Berry announces a new position
Hello Readers,
As some of you will already have heard, I have accepted the position of Business Intelligence Director at TripAdvisor for Business--the part of TripAdvsor that sells products and services to businesses rather than consumers. The largest part of T4B as this side of the business is called internally is selling direct links to hotel web sites that appear right next to the hotel reviews on TripAdvisor.com. Subscribers are also able to make special offers ("free parking", "20% off", "a free bottle of wine with your meal", . . .) directly on the TripAdvisor site. Another T4B product is listings for vacation rental properties. There is a lot of data, and a lot of questions to be answered!
I will continue to contribute to this blog and I will continue to work with Gordon and Brij on the data mining courses that Data Miners produces. TripAdvisor is based in Newton, Massachusetts--not far from my home in Cambridge. It will be novel going home every night after work!
-Michael
As some of you will already have heard, I have accepted the position of Business Intelligence Director at TripAdvisor for Business--the part of TripAdvsor that sells products and services to businesses rather than consumers. The largest part of T4B as this side of the business is called internally is selling direct links to hotel web sites that appear right next to the hotel reviews on TripAdvisor.com. Subscribers are also able to make special offers ("free parking", "20% off", "a free bottle of wine with your meal", . . .) directly on the TripAdvisor site. Another T4B product is listings for vacation rental properties. There is a lot of data, and a lot of questions to be answered!
I will continue to contribute to this blog and I will continue to work with Gordon and Brij on the data mining courses that Data Miners produces. TripAdvisor is based in Newton, Massachusetts--not far from my home in Cambridge. It will be novel going home every night after work!
-Michael
Friday, April 1, 2011
Data Mining Techniques 3rd Edition
Gordon and I spent much of the last year writing the third edition of Data Mining Techniques and now, at last, I am holding the finished product in my hand. In the 14 years since the first edition came out, our knowledge has increased by a factor of at least 10 while the page count has only doubled so I estimate the information density has increased by a factor of five! I hope reviewers will agree that our writing skills have also improved with time and practice. In short, I'm very proud of our latest effort and I hope our readers will continue to find it useful for the next 14 years!

Table of Contents
Chapter 1 What Is Data Mining and Why Do It? 1
Chapter 2 Data Mining Applications in Marketing and Customer Relationship Management 27
Chapter 3 The Data Mining Process 67
Chapter 4 Statistics 101: What You Should Know About Data 101
Chapter 5 Descriptions and Prediction: Profi ling and Predictive Modeling 151
Chapter 6 Data Mining Using Classic Statistical Techniques 195
Chapter 7 Decision Trees 237
Chapter 8 Artifi cial Neural Networks 283
Chapter 9 Nearest Neighbor Approaches: Memory-Based Reasoning and Collaborative Filtering 323
Chapter 10 Knowing When to Worry: Using Survival Analysis to Understand Customers 359
Chapter 11 Genetic Algorithms and Swarm Intelligence 399
Chapter 12 Tell Me Something New: Pattern Discovery and Data Mining 431
Chapter 13 Finding Islands of Similarity: Automatic Cluster Detection 461
Chapter 14 Alternative Approaches to Cluster Detection 501
Chapter 15 Market Basket Analysis and Association Rules 537
Chapter 16 Link Analysis 583
Chapter 17 Data Warehousing, OLAP, Analytic Sandboxes, and Data Mining 615
Chapter 18 Building Customer Signatures 657
Chapter 19 Derived Variables: Making the Data Mean More 695
Chapter 20 Too Much of a Good Thing? Techniques for Reducing the Number of Variables 737
Chapter 21 Listen Carefully to What Your Customers Say: Text Mining 777
Index 823
Table of Contents
Chapter 1 What Is Data Mining and Why Do It? 1
Chapter 2 Data Mining Applications in Marketing and Customer Relationship Management 27
Chapter 3 The Data Mining Process 67
Chapter 4 Statistics 101: What You Should Know About Data 101
Chapter 5 Descriptions and Prediction: Profi ling and Predictive Modeling 151
Chapter 6 Data Mining Using Classic Statistical Techniques 195
Chapter 7 Decision Trees 237
Chapter 8 Artifi cial Neural Networks 283
Chapter 9 Nearest Neighbor Approaches: Memory-Based Reasoning and Collaborative Filtering 323
Chapter 10 Knowing When to Worry: Using Survival Analysis to Understand Customers 359
Chapter 11 Genetic Algorithms and Swarm Intelligence 399
Chapter 12 Tell Me Something New: Pattern Discovery and Data Mining 431
Chapter 13 Finding Islands of Similarity: Automatic Cluster Detection 461
Chapter 14 Alternative Approaches to Cluster Detection 501
Chapter 15 Market Basket Analysis and Association Rules 537
Chapter 16 Link Analysis 583
Chapter 17 Data Warehousing, OLAP, Analytic Sandboxes, and Data Mining 615
Chapter 18 Building Customer Signatures 657
Chapter 19 Derived Variables: Making the Data Mean More 695
Chapter 20 Too Much of a Good Thing? Techniques for Reducing the Number of Variables 737
Chapter 21 Listen Carefully to What Your Customers Say: Text Mining 777
Index 823
Tuesday, March 22, 2011
How to calculate R-squared for a decision tree model
A client recently wrote to us saying that she liked decision tree models, but for a model to be used at her bank, the risk compliance group required an R-squared value for the model and her decision tree software doesn't supply one. How should she fill in the blank? There is more than one possible answer.
Start with the definition of R-squared for regular (ordinary least squares) regression. There are three common ways of describing it. For OLS they all describe the same calculation, but they suggest different ways of extending the definition to other models. The calculation is 1 minus the ratio of the sum of the squared residuals to the sum of the squared differences of the actual values from their average value.
The denominator of this ratio is the variance and the numerator is the variance of the residuals. So one way of describing R-squared is as the proportion of variance explained by the model.
A second way of describing the same ratio is that it shows how much better the model is than the null model which consists of not using any information from the explanatory variables and just predicting the average. (If you are always going to guess the same value, the average is the value that minimizes the squared error.)
Yet a third way of thinking about R-squared is that it is the square of the correlation r between the predicted and actual values. (That, of course, is why it is called R-squared.)
Back to the question about decision trees: When the target variable is continuous (a regression tree), there is no need to change the definition of R-squared. The predicted values are discrete, but everything still works.
When the target is a binary outcome, you have a choice. You can stick with the original formula. In that case, the predicted values are discrete with values between 0 and 1 (as many distinct estimates as the tree has leaves) and the actuals are either 0 or 1. The average of the actuals is the proportion of ones (i.e. the overall probability of being in class 1). This method is called Efron's pseudo R-squared.
Alternatively, you can say that the job of the model is to classify things. The null model would be to always predict the most common class. A good pseudo R-squared is how much better does your model do? In other words, the ratio of the proportion correctly classified by your model to the proportion of the most common class.
There are many other pseudo R-squares described on a page put up by the statistical consulting services group at UCLA.
Start with the definition of R-squared for regular (ordinary least squares) regression. There are three common ways of describing it. For OLS they all describe the same calculation, but they suggest different ways of extending the definition to other models. The calculation is 1 minus the ratio of the sum of the squared residuals to the sum of the squared differences of the actual values from their average value.
The denominator of this ratio is the variance and the numerator is the variance of the residuals. So one way of describing R-squared is as the proportion of variance explained by the model.
A second way of describing the same ratio is that it shows how much better the model is than the null model which consists of not using any information from the explanatory variables and just predicting the average. (If you are always going to guess the same value, the average is the value that minimizes the squared error.)
Yet a third way of thinking about R-squared is that it is the square of the correlation r between the predicted and actual values. (That, of course, is why it is called R-squared.)
Back to the question about decision trees: When the target variable is continuous (a regression tree), there is no need to change the definition of R-squared. The predicted values are discrete, but everything still works.
When the target is a binary outcome, you have a choice. You can stick with the original formula. In that case, the predicted values are discrete with values between 0 and 1 (as many distinct estimates as the tree has leaves) and the actuals are either 0 or 1. The average of the actuals is the proportion of ones (i.e. the overall probability of being in class 1). This method is called Efron's pseudo R-squared.
Alternatively, you can say that the job of the model is to classify things. The null model would be to always predict the most common class. A good pseudo R-squared is how much better does your model do? In other words, the ratio of the proportion correctly classified by your model to the proportion of the most common class.
There are many other pseudo R-squares described on a page put up by the statistical consulting services group at UCLA.
Friday, March 11, 2011
Upcoming talks and classes
Michael will be doing a fair amount of teaching and presenting over the next several weeks:
March 16-18 Data Mining Techniques Theory and Practice at SAS Institute in Chicago.
March 29 Applying Survival Analysis to Forecasting Subscriber Levels at the New England Statistical Association Meeting.
April 7 Predictive Modeling for the Non-Statistician at the TDWI conference in Washington, DC.
March 16-18 Data Mining Techniques Theory and Practice at SAS Institute in Chicago.
March 29 Applying Survival Analysis to Forecasting Subscriber Levels at the New England Statistical Association Meeting.
April 7 Predictive Modeling for the Non-Statistician at the TDWI conference in Washington, DC.
Thursday, March 3, 2011
Cluster Silhouettes
The book is done! All 822 pages of the third edition of Data Mining Techniques for Marketing, Sales, and Customer Relationship Management will be hitting bookstore shelves later this month or you can order it now. To celebrate, I am returning to the blog.
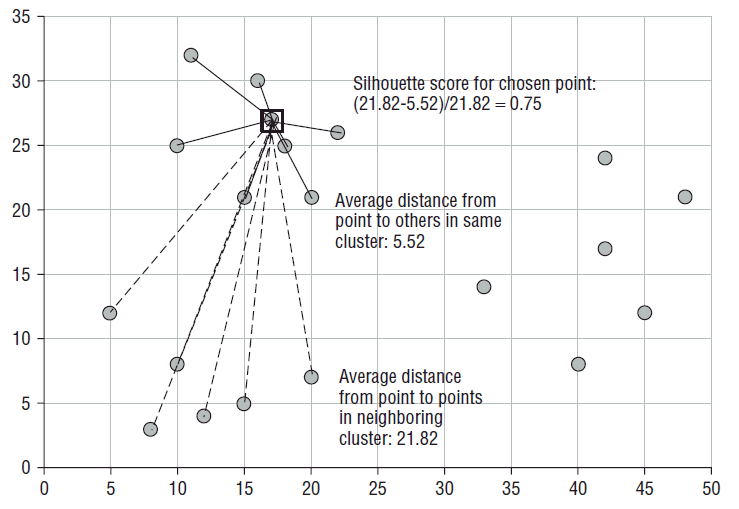
One of the areas where Gordon and I have added a lot of new material is clustering. In this post, I want to share a nice measure of cluster goodness first described by Peter Rousseeuw in 1986. Intuitively, good clusters have the property that cluster members are close to each other and far from members of other clusters. That is what is captured by a cluster's silhouette.
To calculate a cluster’s silhouette, first calculate the average distance within the cluster. Each cluster member has its own average distance from all other members of the same cluster. This is its dissimilarity from its cluster. Cluster members with low dissimilarity are comfortably within the cluster to which they have been assigned. The average dissimilarity for a cluster is a measure of how compact it is. Note that two members of the same cluster may have different neighboring clusters. For points that are close to the boundary between
two clusters, the two dissimilarity scores may be nearly equal.
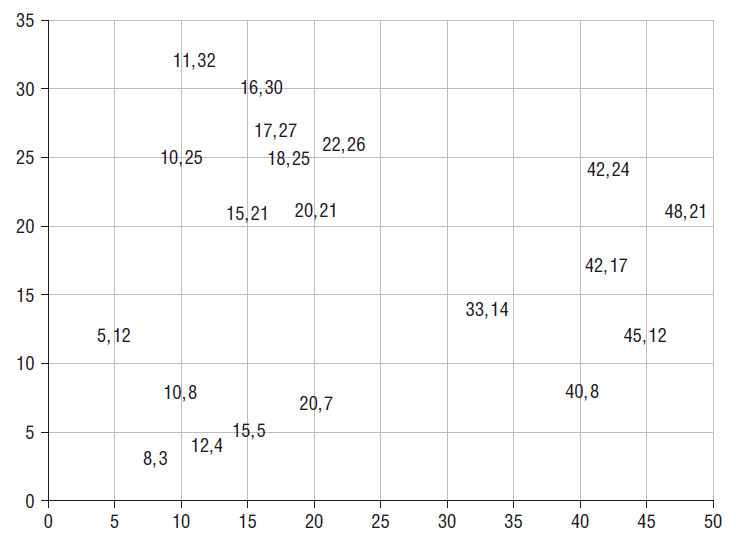
The average distance to fellow cluster members is then compared to the average distance to members of the neighboring cluster. The pictures below show this process for one point (17, 27).
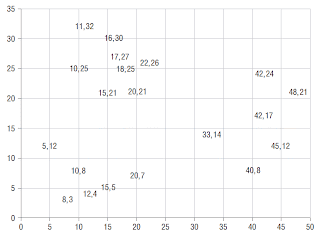
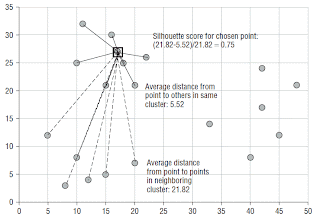
The ratio of a point's dissimilarity to its own cluster to its dissimilarity with its nearest neighboring cluster is its silhouette. The typical range of the score is from zero when a record is right on the boundary of two clusters to one when it is identical to the other records in its own cluster. In theory, the silhouette score can go from negative one to one. A negative value means that the record is more similar to the records of its neighboring
cluster than to other members of its own cluster. To see how this could happen, imagine forming clusters using an agglomerative algorithm and single-linkage distance. Single-linkage says the distance from a point to a cluster is the distance to the nearest member of that cluster. Suppose the data consists of many records with the value 32 and many others with the value 64 along with a scattering of records with values from 32 to 50. In the first step, all the records at distance zero are combined into two tight clusters. In the next step, records distance one away are combined causing some 33s to be added to the left cluster followed by 34s, 35s, etc. Eventually, the left cluster will swallow records that would feel happier in the right cluster.
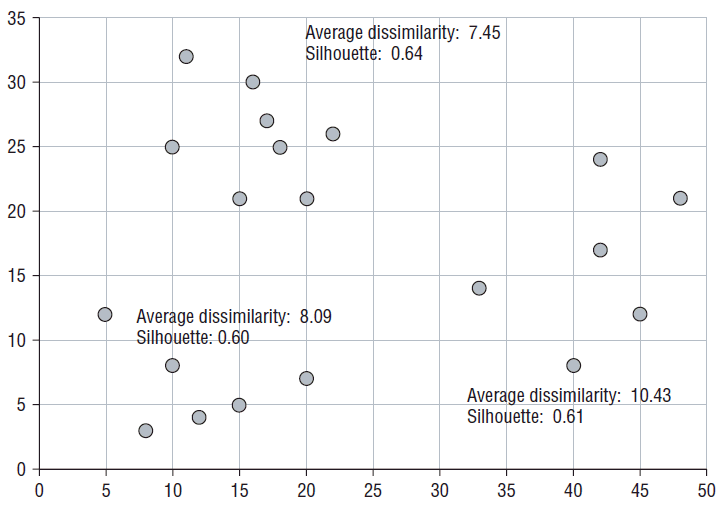
The silhouette score for an entire cluster is calculated as the average of the silhouette scores of its members. This measures the degree of similarity of cluster members. The silhouette of the entire dataset is the average of the silhouette scores of all the individual records. This is a measure of how appropriately the data has been
clustered. What is nice about this measure is that it can be applied at the level of the dataset to determine which clusters are not very good and at the level of a cluster to determine which members do not fit in very well. The silhouette can be used to choose an appropriate value for k in k-means by trying each value of
k in the acceptable range and choosing the one that yields the best silhouette. It can also be used to compare clusters produced by different random seeds.
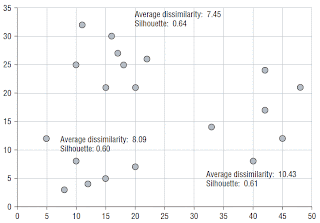
The final picture shows the silhouette scores for the three clusters in the example.
One of the areas where Gordon and I have added a lot of new material is clustering. In this post, I want to share a nice measure of cluster goodness first described by Peter Rousseeuw in 1986. Intuitively, good clusters have the property that cluster members are close to each other and far from members of other clusters. That is what is captured by a cluster's silhouette.
To calculate a cluster’s silhouette, first calculate the average distance within the cluster. Each cluster member has its own average distance from all other members of the same cluster. This is its dissimilarity from its cluster. Cluster members with low dissimilarity are comfortably within the cluster to which they have been assigned. The average dissimilarity for a cluster is a measure of how compact it is. Note that two members of the same cluster may have different neighboring clusters. For points that are close to the boundary between
two clusters, the two dissimilarity scores may be nearly equal.
The average distance to fellow cluster members is then compared to the average distance to members of the neighboring cluster. The pictures below show this process for one point (17, 27).
The ratio of a point's dissimilarity to its own cluster to its dissimilarity with its nearest neighboring cluster is its silhouette. The typical range of the score is from zero when a record is right on the boundary of two clusters to one when it is identical to the other records in its own cluster. In theory, the silhouette score can go from negative one to one. A negative value means that the record is more similar to the records of its neighboring
cluster than to other members of its own cluster. To see how this could happen, imagine forming clusters using an agglomerative algorithm and single-linkage distance. Single-linkage says the distance from a point to a cluster is the distance to the nearest member of that cluster. Suppose the data consists of many records with the value 32 and many others with the value 64 along with a scattering of records with values from 32 to 50. In the first step, all the records at distance zero are combined into two tight clusters. In the next step, records distance one away are combined causing some 33s to be added to the left cluster followed by 34s, 35s, etc. Eventually, the left cluster will swallow records that would feel happier in the right cluster.
The silhouette score for an entire cluster is calculated as the average of the silhouette scores of its members. This measures the degree of similarity of cluster members. The silhouette of the entire dataset is the average of the silhouette scores of all the individual records. This is a measure of how appropriately the data has been
clustered. What is nice about this measure is that it can be applied at the level of the dataset to determine which clusters are not very good and at the level of a cluster to determine which members do not fit in very well. The silhouette can be used to choose an appropriate value for k in k-means by trying each value of
k in the acceptable range and choosing the one that yields the best silhouette. It can also be used to compare clusters produced by different random seeds.
The final picture shows the silhouette scores for the three clusters in the example.
Tuesday, October 5, 2010
Interview with Michael Berry
We haven't been updating the blog much recently. Data mining blogger, Ajay Ohri figured out why. We have been busy working on a new edition of Data Mining Techniques. He asked me about that in this interview for his blog.
Subscribe to:
Posts (Atom)



{kind=link}