It's been a while since I posted. My new role at TripAdvisor has been keeping me pretty busy! My first post after a long absence is about a feature of SQL that I have recently fallen in love with. Usually, I leave it to Gordon to write about SQL since he is an expert in that field, but this particular feature is one that he doe not write about in
Data Analysis Using SQL and Excel. The feature is called
common table expressions or, more simply, the WITH statement.
Common table expressions allow you to name a bunch of useful subquerries before using them in your main query. I think of the common table expressions as subquerries because that is what they usually replace in my code, but they are actually a lot more convenient than subquerries because they aren't "sub". They are there at the top level so your main query can refer to them as many times as you like anywhere in the query. In that way, they are more like temporary tables or views. Unlike tables and views, however, you don't have to be granted permission to create them, and you don't have to remember to clean them up when you are done. Common table expressions last only as long as the query is running.
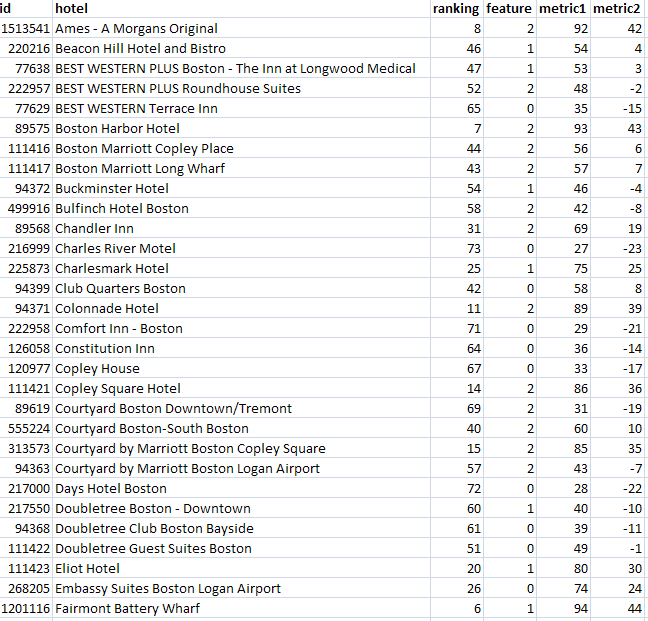
An example will help show why common table expressions are so useful. Suppose (because it happens to be true) that I have a complicated query that returns a list of hotels along with various metrics. These could be as simple as the number of rooms, or the average daily rate, or the average rating by our reviewers, or it could be a complex expression to produce a model score. For this purpose, it doesn't matter what the metric is, what matters is that I want to compare "similar" properties for some definition of similar. The first few rows returned by my complicated query look something like this:

Similar hotels have the same value of
feature and similar ranking. In fact, I want to compare each hotel with four others: The one with matching feature that is next above it in rank, the one with matching feature that is next below it in rank, the one with non-matching feature that is next above it in rank, and the one with non-matching feature that is next below it in rank. Of course, for any one hotel, some of these neighbors may not exist. The top ranked hotel has no neighbors above it, for instance.
My final query involves joining the result pictured above with itself four times using non-equi joins, but for simplicity, I'll leave out the matching and non-matching features bit and simply compare each hotel to the one above and below it in rank. The ranking column is dense, so I can use equi joins on ranking=ranking+1 and ranking=ranking-1 to achieve this. Here is the query:
with ranks (id, hotel, ranking, feature, metric1, metric2)
as(select . . .) /* complicated query to get rankings */
select r0.id, r0.hotel,
r0.metric1 as m1_self, r1.metric1 as m1_up, r2.metric1 as m1_down
from ranks r0 /* each hotel */ left join
ranks r1 on r0.ranking=r1.ranking+1 /* the one above */ left join
ranks r2 on r0.ranking=r2.ranking-1 /* the one below */
order by r0.ranking
The common table expression gives my complicated query the name
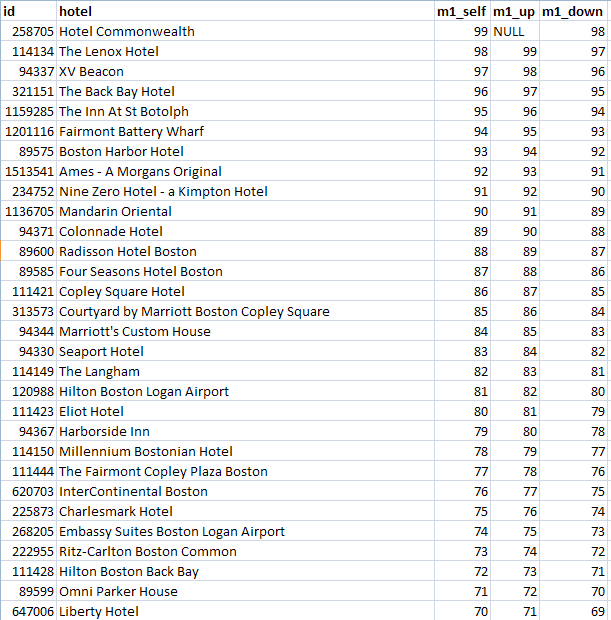
ranks. In the main query, ranks appears three times with aliases r0, r1, and r2. The outer joins ensure that I don't lose a hotel just because it is missing a neighbor above or below. The query result looks like this:
The Hotel Commonwealth has the highest score, a 99, so there is nothing above it. In this somewhat contrived example, the hotel below it is the Lenox with a score of 98 and so on down the list. To write this query using subqueries, I would have had to repeat the subquery three times which would not only be ugly, it would risk actually running the subquery three times since the query analyzer might not notice that they are identical.