Euclidean geometry, formalized in Euclid's Elements about 2,300 years ago, is in many ways a study of lines and circles. One might think that after more than two millennia, we have moved beyond such basic shapes particularly in a realm such as data mining. I don't think that is so true.
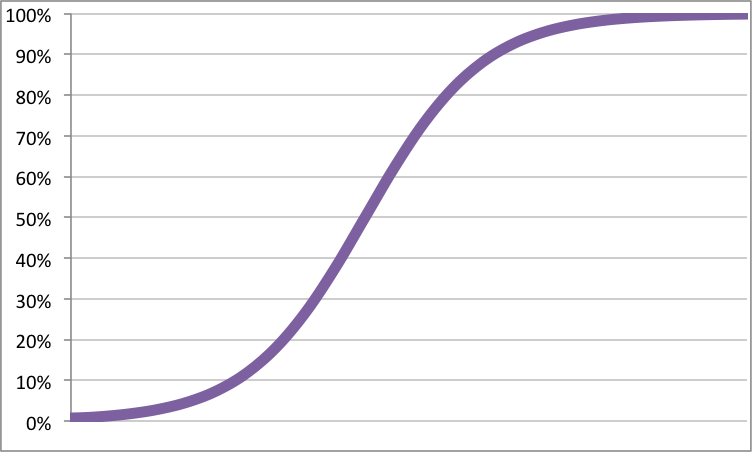

One of the overlooked aspects of logistic regression is how it is fundamentally looking for a line (or a plane or a hyperplane in multiple dimensions). When most people learn about logistic regression, they start with an understanding of the sinuous curve associated with it (you can check out the Wikipedia page, for instance). Something like this in one dimension:
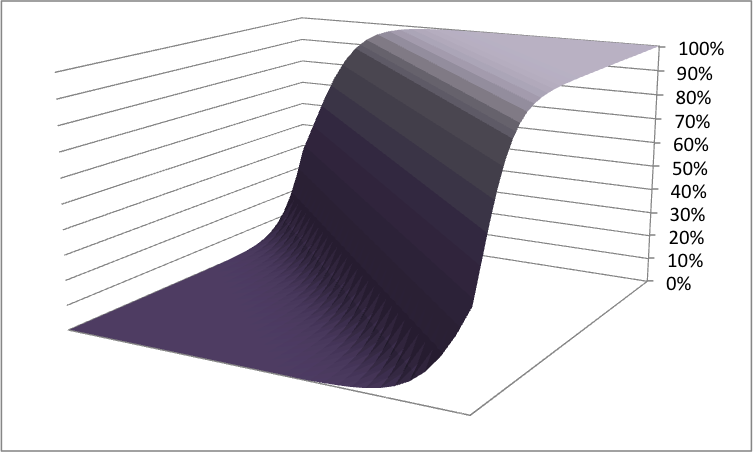
Or like this in two dimensions:
These types of pictures suggest that logistic regression is sinuous and curvaceous. They are actually misleading. Although the curve is sinuous and curvaceous, what is important is the boundary between the high values and the low values. This separation boundary is typically a line or hyperplane; it is where the value of the logistic regression is 50%. Or, assuming that the form of the regression is:
logit(x) = f(x) = a*x + y
Then it is where the f(x) is set to 0. What does this look like? A logistic regression divides the space into two parts, one part to the "left" (or "above") the line/hyperplane and one part to the "right" (or "below"). A given line just splits the plane into two parts:
In this case, the light grey would be "0" (that is, less than 50%) and the blue "1" (that is, greater than 50%). The boundary is where the logistic function takes on the value 50%.
Note that this is true even when you build a logistic regression sparse data. For instance, if your original data has about 5% 1s and 95% 0s, the average value of the resulting model on the input data will be about 5%. However, somewhere in the input space, the logistic regression will take on the value of 50%, even if there is no data there. Even if the interpretation of a point in that area of the data space is non-sensical (the customer spends a million dollars a year and hasn't made a purchase in 270 years, or whatever). The line does exist, separating the 0s from the 1s, even when all the data is on one side of that line.
What difference does this make? Logistic regression models are often very powerful. More advanced techniques, such as decision trees, neural networks, and support-vector machines, offer incremental improvement, and often not very much. And often, that improvement can be baked back into a logistic regression model by a adding one or more derived variables.
What is happening is that the input variables (dimensions) for the logistic regression are chosen very carefully. In a real situation (as opposed to the models one might build in a class), much thought and care has gone into the choice of variables and how they are combined to form derived variables. As a result, the data has been stretched and folded in such a way that different classification values tend to be on different "side"s of the input space.
This manipulation of the inputs helps not only logistic regression but almost any technique. Although the names are fancier and the computing power way more advanced, very powerful techniques rely on geometries studied 2,300 years ago in the ancient world.


