This post is about creating a Venn diagram using two circles. A Venn diagram is used to explain data such as:
- Group A has 81 members.
- Group B has 25 members.
- There are 15 members in both groups A and B.

Unfortunately, creating a simple Venn diagram is not built into Excel, so we need to create one manually. This is another example that shows off the power of Excel charting to do unexpected things.
Specifically, creating the above diagram requires the following capabilities:
- We need to draw a circle with a given radius and a center at any point.
- We need to fill in the circle with appropriate shading.
- We need to calculate the appropriate centers and radii given data.
- We need to annotate the chart with text.
Drawing a Circle Using Scatter Plots
To create the circle, we start with a bunch of points, that when connected with smoothed lines will look like a circle. To get the points, we'll create a table with values from 0 to 360 degrees, and borrow some formulas from trigonometry. These say:
- X = radius*sin(
) + X-offset - Y = radius*cos(
) + Y-offset
- X = radius*sin(
*2*PI/360) + X-offset - Y = radius*cos(
*2*PI/360) + Y-offset
| Degrees | X-Value | Y-Value | |
| 0 | =$E$4+SIN(2*PI()*B11/360)*$D$4 | =$F$4+COS(2*PI()*B11/360)*$D$4 | |
| 5 | =$E$4+SIN(2*PI()*B12/360)*$D$4 | =$F$4+COS(2*PI()*B12/360)*$D$4 | |
| 10 | =$E$4+SIN(2*PI()*B13/360)*$D$4 | =$F$4+COS(2*PI()*B13/360)*$D$4 | |
| 15 | =$E$4+SIN(2*PI()*B14/360)*$D$4 | =$F$4+COS(2*PI()*B14/360)*$D$4 | |
| 20 | =$E$4+SIN(2*PI()*B15/360)*$D$4 | =$F$4+COS(2*PI()*B15/360)*$D$4 | |
| 25 | =$E$4+SIN(2*PI()*B16/360)*$D$4 | =$F$4+COS(2*PI()*B16/360)*$D$4 | |
| 30 | =$E$4+SIN(2*PI()*B17/360)*$D$4 | =$F$4+COS(2*PI()*B17/360)*$D$4 |
Where E4 contains the X-offset; F4 contains the Y-offset; and D4 contains the radius.
The degree values need to extend all the way to 360 to get a full circle, which can then be plotted as a scatter plot. When choosing which variety of the scatter plot, choose the option of points connected with smoothed lines.
The following chart shows the resulting circle with the points highlighted, along with axis labels and grid lines (which should be removed before creating the final version):

Creating a second circle is as easy as creating one, by just adding a second set of series onto the chart.
Filling in the Circle with Appropriate Shading
Unfortunately, to Excel, the circle is really just a collection of points, and we cannot fill it with shading. However, with a clever idea of using error bars, we can put in a pattern, such as:
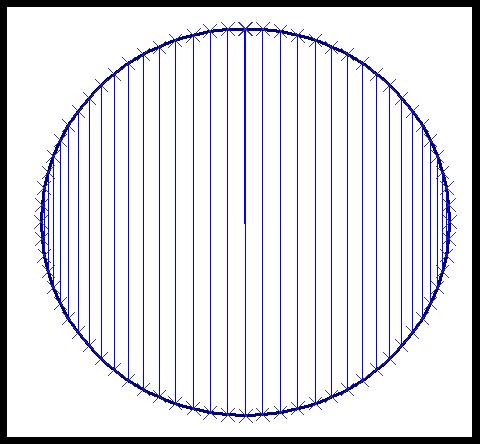
The idea is to create X error bars for horizontal lines and Y error bars for vertical lines. To do this. right click on the circle and choose "Format Data Series". Then go to the "X Error Bars" or "Y Error Bars" tab (whichever is appropriate). Put 101 in the "Percent" box.
This adds the error bars. To format then, double click on one of them. You can set the color for them and also remove the little line at the edge.
You will notice that these bars are not evenly spaced. The spacing is related to the degrees. With the proper choice of degrees, the points would be evenly spaced. However, I do not mind the uneven spacing, and have not bothered to figure out a better set of points for even spacing.
Calculating Where the Circles Should Be
Given the area of a circle, calculating the radius is a simple matter of reversing the area formula. So, we have:
- radius = SQRT(area/PI())
Unfortunately, there is no easy solution. First, we have to apply some complicated arithmetic to calculate the overlap between two circles, given a width of the overlap. Then we have to find the overlap that gives the correct area.
The first part is solved by finding the area of overlap between two circules, at a site such as Wolfram Math World.
The second is solved by using the "Goal Seek" functionality under the tools bar. We simple set up a worksheet that calculates the area of the overlap, given the width of the overlap and the two radii. One of the cells has the difference between this value and the area that we want. We then use Goal Seek to set this value to 0.
Annotating the Chart with Text
The final step is annotating the chart with text, such as "A Only: 65". First, we put this string in a cell, using a formula such as:
- ="A Only: "&C4-C6
Publish Post
In the end, we are able to create an accurate Venn diagram with two circles, of any size and overlap.
venn-20080112.xls





