For the longitudinal patient data, the groups were repeated measurements on the same individual. For this discussion though, I'll ask questions such as "How much of the variation in zip code population is due to variations within a state versus variations between states?" I leave it to the reader to generalize this to other areas.
The data used is the census data on the companion web site to my book . Also, the spirit of understanding this problem using SQL and charts also comes from the book.
This posting starts with what I consider to be a simple approach to answering the question. It is then going to show how to calculate the result in SQL. Finally, I'm going to discuss the solution Paul Allison prsents in his book, and what I think are its drawbacks.
What Does Within- Versus Between- Group Variation Even Mean?
I first saw this issue in Paul Allison's book Fixed Effects Regression Methods for Longitudinal Data Analysis Using SAS, which became something of a bible on the subject while I was trying to do exactly what the title suggested (and I highly, highly recommend the book for people tackling such problems). On page 40, he has the tantalizing observation "The degree to which the coefficients change under fixed effects estimation as compared with conventional OLS appears to be related to the degree of between- versus within-school variation on the predictor variables."
This suggests that within-group versus between-group variation can be quite interesting. And not just for predictor variables. And not just for schools.
Let's return to the question of how much variation in a zip code's population is due to the state where the zip code resides, and how much is due to variation within the state. To answer this question analytically, we need to phrase it in terms of measures. Or, for this question, how well does the average population of zip codes in a state do at predicting the population of a zip code in the state?
In answering this question, we are replacing the values of individual zip codes with the averaged values at the group (i.e. state) level. By eliminating within group variation, the answer will tell us about between-group variation. We can assume that remaining variation is due to within group variation.
Using Variation to Answer the Question
Variance quantifies the idea that each point -- say the population of each zip code -- differs from the overall average. The following chart shows a scatter plot of all the zip codes with the overall average (by the way, the zip codes here are ordered by the average zip code population in each state).
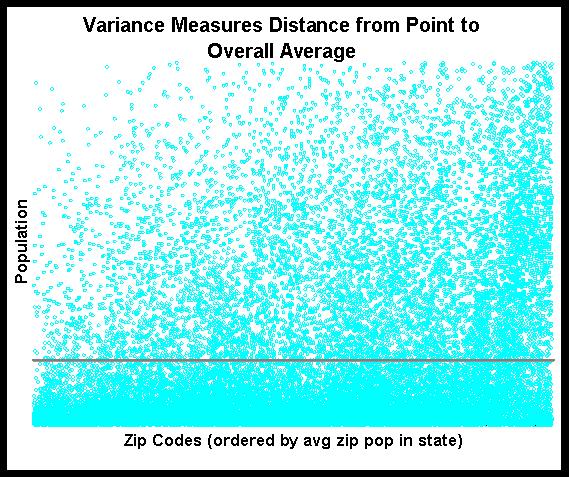 The grey line is the overall average. We can see that the populations for zip codes are all over the place; there is not much of a pattern. As for the variance calculation, imagine a bar from each point to the horizontal line. The variance is just the sum of the squared distances from each point to the average. This sum is the total variance.
The grey line is the overall average. We can see that the populations for zip codes are all over the place; there is not much of a pattern. As for the variance calculation, imagine a bar from each point to the horizontal line. The variance is just the sum of the squared distances from each point to the average. This sum is the total variance.What we want to do is to decompose this variance into two parts, a within-group part and a between-groups part. I think the second is easier to explain, so let me take that route. To eliminate within group variation, we just substitute the average value in the group for the actual value. This means that we are looking at the following chart instead:
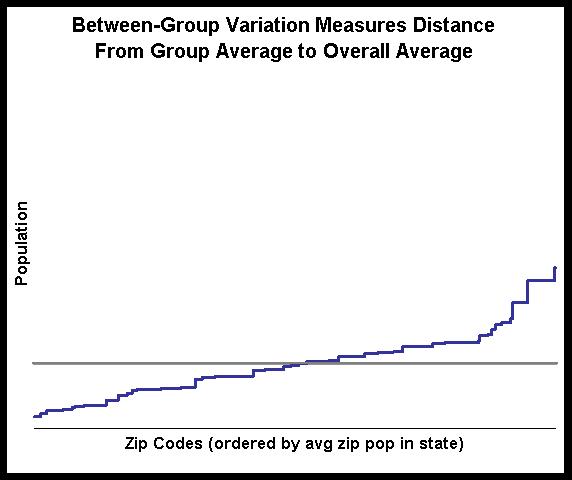 The blue slanted line is the average in each state. We see visually that much of the variation has gone away, so we would expect most variation to be within a state rather than between states.
The blue slanted line is the average in each state. We see visually that much of the variation has gone away, so we would expect most variation to be within a state rather than between states.The idea is that we measure the variation using the first approach and we measure the variation using the second approach. The ratio of these two values tells us how much of the variation is due to between-groups changes. The remaining variation must be due to within-group variation. The next section shows the calculation in SQL.
Doing the Calculation in SQL
Expressing this in SQL is simply a matter of calculating the various sums of squared differences. The following SQL statement calculates both the within-group and between-group variation:
SELECT (SUM((g.grpval - a.allval)*(g.grpval - a.allval))/
........SUM((d.val - a.allval)*(d.val - a.allval))
.......) as between_grp,
.......(SUM((d.val - g.grpval)*(d.val - g.grpval)) /
........SUM((d.val - a.allval)*(d.val - a.allval))
.......) as within_grp
FROM (SELECT state as grp, population as val
......FROM censusfiles.zipcensus zc
.....) d JOIN
.....(SELECT state as grp, AVG(population) as grpval
......FROM censusfiles.zipcensus zc
......GROUP BY 1
.....) g
.....ON d.grp = g.grp CROSS JOIN
.....(SELECT AVG(population) as allval
......FROM censusfiles.zipcensus zc
.....) aFirst note that I snuck in the calculation for both within- and between- group variation, even though I only explained the latter.
The from clause has three subqueries. Each of these calculates one level of the summary -- the value for each zip, the value for each state, and the overall value. All the queries rename the fields to some canonical name. This means that we can change the field we are looking at and not have to modify the outer SELECT clause -- a convenience that reduces the chance of error.
In addition, the structure of the query makes it fairly easy to use a calculated field rather than just a column. The same calculation would need to be used for all the fields.
And finally, if you are using a database that supports window functions -- such as SQL Server or Oracle -- then the statement for the query can be much simpler.
Discussion of Results
The results for population say that 12.6% of the variation in zip code population is between states and 87.4% is within states. This confirms the observation that using the state averages removed much of the variation in the data. In fact, for most of the census variables, most of the variation is within states.
There are definitely exceptions to this. One interesting exception is latitutude (which specifies how far north or south something is). The within-state variation for latitude is 5.5% and the between-state is 94.5% -- quite a reversal. The scatter plot for latitude looks quite different from the scatter plot for population:
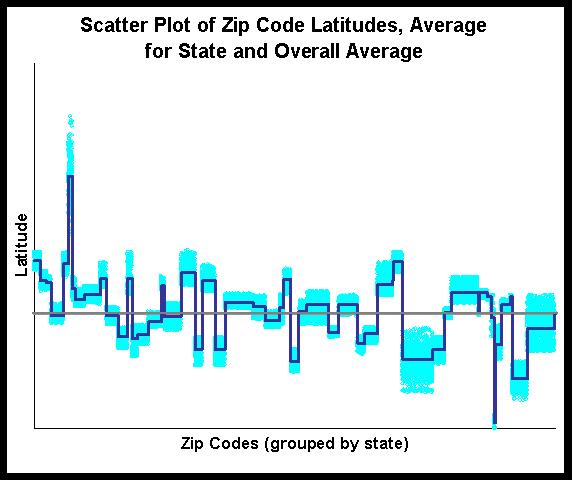
In this scatter plot, we see that the zip code values in light blue all fall quite close to the average for the state -- and in many cases, quite far from the county average. This makes a lot of sense geographically, and we see that fact both in the scatter plot and in the within-group and between-group variation.
Statistical Approach
Finally, it is instructive to go back to Paul Allison's book and look at his method for doing the same calculation in SAS. Although I am going to show SAS code, understanding the idea does not require knowing SAS -- on the other hand, it might require an advanced degree in statistics.
His proposed method is to run the following statement:
proc glm data=censusfiles.zipcensus;
....absorb state;
....model population=;
run;And, as he states, "the proportion of variation that is between [states] is just the R-squared from this regression."
This statement is called a procedure (or proc for short) in SAS. It is calling the procedure called "glm", which stands for generalized linear model. Okay, now you can see where the advanced statistics might help.
The "absorb" option creates a separate indicator for each state. However, for performance reasons, "abosrb" does not report their values. (There are other ways to do a similar calculation that do report the individual values, but they take longer to run.)
The "model" part of the statement says what model to build. In this case, the model is predicting population, but not using any input variables. Actually, it is using input variables -- the indicators for each state created on the "absorb" line.
Doing the calculation using this method has several shortcomings. First, the results are put into a text file. They cannot easily be captured into a database table or into Excel. You have to search through lots of text to find the right metric. And, you can only run one variable at a time. In the SQL method, adding more variables is just adding more calculations on the SELECT list. And the SQL method seems easier to generalize, which I might bring up in another posting.
However, the biggest shortcoming is conceptual. Understanding variation between-groups and within-groups is not some fancy statistical procedure that requires in-depth knowledge to use correctly. Rather, it is a fundamental way of understanding data, and easy to calculate using tools, such as databases, that can readily manipulate data. The method in SQL should not only perform better on large data sets (particularly using a parallel database), but it requires much less effort to understand.