Thursday, November 14, 2013
What will I do on my Caribbean vacation? Teach data mining, of course!
Wednesday, September 25, 2013
For Predictive Modeling, Big Data Is No Big Deal
Sunday, October 21, 2012
Catch our Webcast on November 15
Tuesday, September 11, 2012
Upcoming Speaking Engagements
This Friday (9/14) I will be at Big Data Innovation talking about how Tripadvisor for Business models subscriber happiness and what we can do to improve a subscriber's probability of renewal.
On October 1 and 2 I will be at Predictive Analytics World in Boston. This has become my favorite data mining conference. On the Monday, I will be visiting with my friends at JMP and giving a sponsored talk about how we use JMP for cannibalization analysis at Tripadvisor for Business. On Tuesday, I will go into the details of that analysis in more detail in a regular conference talk.
Sunday, March 11, 2012
Measuring Site Engagement: Pages or Sessions
A media web site is challenging, because there is no simple definition of engagement or customer worth. The idea is that engagement can either lead to more advertising views or to longer subscriptions, depending on the business model for the site. On the other hand, for a retailing site, the question is simpler, because there is a simple method to see who the best customers are. Namely, the amount of money they spend.
Engagement is a nice marketing concept, but how can it be defined in the real world? One way is to simply look at the number of page views during some period of time. Another is to look at the number of sessions (or alternatively days of activity if sessions are not available) during a specified period of time. Yet another is to measure breadth of usage of the site over a period of time: Does the user only go to one page? Is the user only coming in on referrals from Google?
The first analysis used one month of data to define engagement. The top users for one month were determined based on pages and sessions. Of course, there is a lot of overlap between the two groups -- about 60% of the top deciles overlapped.
Which group seems better for defining engagement, the top users by page views or by sessions? To answer this, let's borrow an idea from survival and measure how many users are still around nine months later. (Nine months is arbitrary in this case). In this case, the return rate for the top decile for sessions was 74.4% but for the top decile for pages was lower at 73.8%. Not a big difference, but one that suggests that sessions are better.
Actually, the results are even more striking for visitors who are not in both top deciles. For the non-overlapping group, the session return rate is69.6% versus 67.9% for the page deciles.
For defining engagement, we then extended these results to three months instead of one to find the top one million most engaged users. The three measures are:
- Visitors that have the most page views over three months.
- Visitors that have the most sessions over three months.
- Visitors in the top tercile of sessions (third) in each month, then take the highest terciles.
Three months was chosen as a rather arbitrary length of time, because the data was available. Holding it constant also lets us understand the difference between sessions and page views.
These three methods all produced about the same number of visitors -- the goal was to find the top one million most engaged users.
By these measures, the top one million visitors chosen by the three methods had the following "return" rates, nine months later:
- Page views in three months: 65.4%
- Sessions in three months: 65.9%
- Sessions over three months: 66.9%
The nine-month survival suggests that the sessions over three months is the better approach for measuring engagement.
Tuesday, February 14, 2012
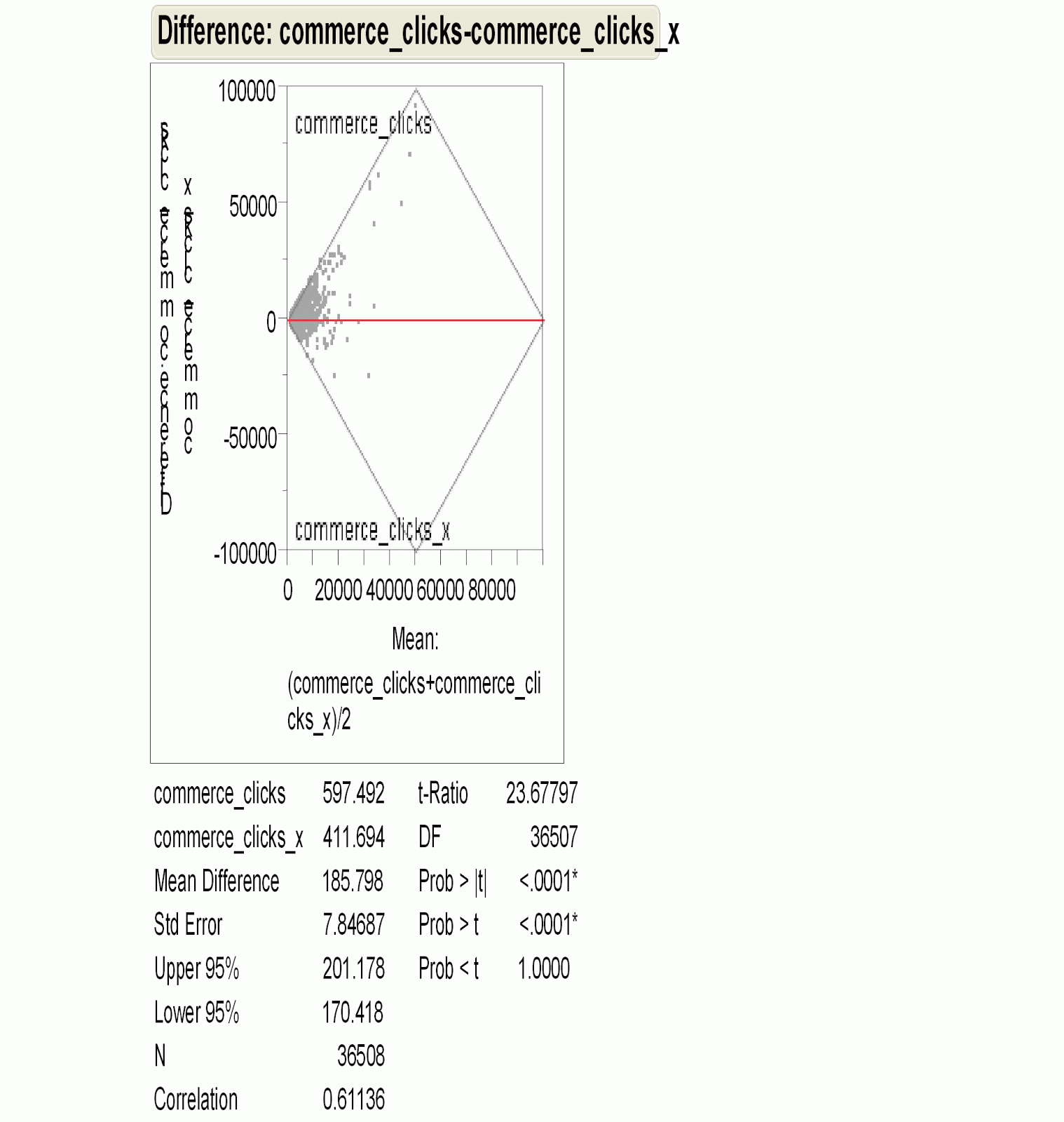
Using Matched Pairs to Test for Cannibalization
Tuesday, January 17, 2012
Writing to a text file from SQL Server
This stored procedure is a utility. I learned a lot along the way while trying to write it. This post is intended to explain these learnings.
The approach that I'm taking is to use xp_cmdshell to write one line at a time using the DOS echo command. A different approach uses OLE automation and the File System Object. I couldn't get this to work, possibly because it requires configurations that I don't know about; possibly because I don't have the right permissions.
My stored procedure is called usp__AppendToFile and the code is at the end of this post. If you care about naming conventions, here is the reasoning behind the name. The "usp" prefix is for user stored procedure. Starting a stored procedure with usp or sp seems redundant to me, but appears to be a common and perhaps even a best practice. The double underscore is my convention, saying that this is a utility. It is then followed by a reasonable name.
usp__AppendToFile does the following: It takes a string (varchar(max)) and an optional end-of-line character. It then writes the string, one line at a time, using the echo command in DOS. By passing in the end of line character, the stored procedure can work with text that uses the DOS standard end of line (carriage return followed by line feed, the default) as well as other standards.
Although seemingly simple and using familiar tools, I learned several things from this effort.
My first lesson is that in order to write to a file, you need to be able to access it. When running you a command in SQL Server, it is not really "you" that needs permissions. The SQL Server service needs to be able to access the file. And this depends on the user running the service. To see this user, go to the Control Panel, choose the Administrative Tools, and select Services. Scroll down to find the SQL Server service (called something like SQL Server Agent), and look in the column Log On As.
As an example, the user running the service on one machine used a local machine account rather than a Windows verified domain account. For this reason, SQL Server could not access files on the network. Changing the service to run on a Windows-authenticated enabled SQL Server to create a file. (The alternative of changing the permissions for the user was not possible, since I do not have network sys admin privileges.)
The second lesson is that in order to write to a file using xp_cmdshell, you need to have xp_cmdshell enabled as shown here. There are good reasons why some DBAs strongly oppose enabling this option, since it does open up a security hole. Well, actually, the security hole is the fault of Microsoft, since the command is either enabled or disabled at the server level. What we really want is to give some users access to it, which denying others.
Third, the DOS way to write text to a file is using the echo command. Nothing is as simple as it seems. Echo does generally write text. However, it cannot write an empty line. Go ahead. Open a CMD shell, type in echo and see what happens. Then type in echo with a bunch of spaces and see what happens. What you get is the informative message: ECHO is on. Thanks a bunch, but that's not echoing what was on the command line.
I want my procedure to write blank lines when it finds them in the string. To fix this problem, use the echo. command. For whatever reason, having the period allows an empty line to be written. Apparently, other characters work as well, but period seems to be the accepted one.
The problems with DOS seem solved, but they are not. DOS has another issue: some special characters are interpreted by DOS, even before echo gets to them. For instance, > is interpreted to put the results to a file; | is interpreted as a pipe between commands, and & is interpreted as a background command. Fortunately, these can be escaped using the DOS escape character, which I'm sure everyone knows is a caret (^).
But, this issue does not end there, because special characters might be in a string, in which case they do not need to be escaped. Parsing a string in a stored procedure to find quotes is beyond the range of this stored procedure. Instead, if there are no double quotes in the string, then it escapes special characters. Otherwise, it does not.
Combining these lessons, here is what I consider to be a useful utility to write a string to a text file, even when the string consists of multiple lines.
CREATE procedure usp__AppendToFile (
@str varchar(max),
@FileName varchar(255),
@EOL varchar(10) = NULL
) as
begin
if @EOL is NULL
begin
set @EOL = char(13) + char(10);
end;
-- the period allows for empty lines
declare @prefix varchar(255) = 'echo.';
declare @suffix varchar(255) = '>>'+@FileName;
-- Escape special characters so things work
-- But escapes work funny when in double quotes (and maybe single quotes too)
set @str = (case when charindex('"', @str) = 0
then replace(replace(replace(@str, '|', '^|'), '>', '^>'), '&', '^&')
else @str
end);
while (@str <> '')
begin
declare @pos int = charindex(@EOL, @str);
declare @line varchar(8000) = (case when @pos > 0 then left(@str, @pos) else @str end);
set @str = (case when @pos > 0 then substring(@str, @pos+2, 1000000) else '' end);
set @line = @prefix+@line+@suffix;
--write @line to file;
exec xp_cmdshell @line;
end;
end; -- usp__AppendToFile


