This post explains what it means to extend chi-square to three dimensions and then to additional dimensions. The key idea in extending the chi-square test is calculating the expected values. The next post discusses how to do the calculations using SQL.
Expected Values
Assume that we have data that takes on a numeric value (typically a count) and has various dimensions, such as the following with dimensions A, B, and C:
| A=0 | B=0 | C=0 | 1 | |
| A=0 | B=0 | C=1 | 2 | |
| A=0 | B=1 | C=0 | 3 | |
| A=0 | B=1 | C=1 | 4 | |
| A=1 | B=0 | C=0 | 5 | |
| A=1 | B=0 | C=1 | 6 | |
| A=1 | B=1 | C=0 | 7 | |
| A=1 | B=1 | C=1 | 8 |
The question that the chi-square test answers is: how expected or unexpected is this data?
What does this question even mean? Well, it means that we have to make some assumptions about the process generating the data -- some reasonable but simple assumptions -- and then measure how well this data matches those expected values.
One possible process is that each cell is independent of all the others. In this case, each cell would, on average, get the same count. To get a total count of 36, each cell would have, on average, a count of 4.5=36/8. Such a uniform distribution does not seem useful, because it does not take into account the structure of the data. "Structure" here means that the data has three dimensions.
The assumption used for chi-square takes this structure into account. It assumes that the process generates values independently along each dimension independently (rather than for each cell or for some arbitrary combination of dimension values). This assumption has some implications.
In the original data, there were ten things in the cells where A=0 (10 =1+2+3+4). The expected values have the same relationship -- the sum of the expected values where A=0 should also be 10. This is true for each of the values along each of the dimensions. Note, though, that it is not true for combinations of dimensions. So, the sum of the expected values where A=0 and B=0 is different (in general) for the expected values and the observed values.
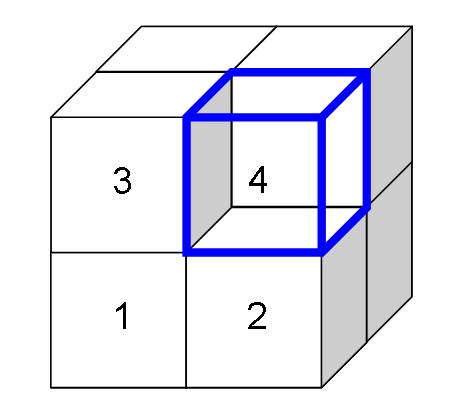
There is a second implication. The distribution of values within each layer (or subcube) is the same, for all layers along the dimension. The following picture illustrates this in three dimensions:
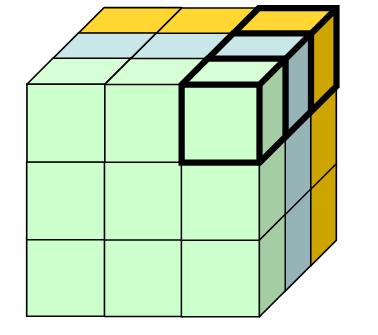 The three shaded layers each have the property that the sums of the expected values are the same as the sums of the original data. In addition, the distributions are the same. This means that the highlighted cell in each layer has the same proportion for all the layers.
The three shaded layers each have the property that the sums of the expected values are the same as the sums of the original data. In addition, the distributions are the same. This means that the highlighted cell in each layer has the same proportion for all the layers.This latter condition is actually quite a strong condition, because it imposes structure between all the cells in different layers.
Calculating Expected Values
There is actually a simple formula for calulating the expected values. The calculation starts with the sums of the values of the cells in each possible layer. The above diagram shows three layers, but this is only along one dimension. There are an additional three layers (or subcubes) along each of the other two dimensions. (The choice of 3 here is totally arbitrary; there could be any number along each dimension.)
The expected value for a cell is the ratio of two numbers:
- The product of the sum of the values along each dimension, divided by
- The sum in the entire table raised to the power of the number of dimensions minus one.
First, we need to calculate the sums for the three layers:
- Asum is the cells where A=0: 10=1+2+3+4
- Bsum is the cells where B=0: 14=1+2+5+6
- Csum is the cells where C=0: 16=1+3+5+7
- The product is 2,240.
The other cells have similar calculations. The following shows the table with the expected values:
| A | B | C | Value | Expected | |
| 0 | 0 | 0 | 1 | 1.73 | |
| 0 | 0 | 1 | 2 | 2.16 | |
| 0 | 1 | 0 | 3 | 2.72 | |
| 0 | 1 | 1 | 4 | 3.40 | |
| 1 | 0 | 0 | 5 | 4.49 | |
| 1 | 0 | 1 | 6 | 5.62 | |
| 1 | 1 | 0 | 7 | 7.06 | |
| 1 | 1 | 1 | 8 | 8.83 |
Here the expected values are pretty close to the original values. This calculation is available in the accompanying spreadsheet (chi-square-blog.xls).
The calculation also readily extends to more than two dimensions. However, the condition that the distrubutions are the same along parallel subcubes becomes more and more restrictive. In two dimensions, the expected values make intuitive sense. However, as the number of dimensions grows. they may not be as intuitive. Also, by combining values along dimensions, it is possible to reduce a multidimensional case to a two-dimensional case (although some information is lost in the process).
From Expected Values to Chi-Square
The chi-square calculation itself follows the same procedure as in the two dimensional case. The chi-square for each cell is the difference between the observed and expected value squared, divided by the expected value. The chi-square for the whole table is the sum of all the chi-square values.
The degrees of freedom is calculated in a way similar to the two-dimensional case. It is the product of the size of each dimension minus 1. So, in the 2X2X2 case, the degrees of freedom is 1. In the 3X3X3X3 case, it is 16 (2*2*2*2).
The next posting will explain how to calculate the expected value using SQL.